
1. データ拡張 (Data Augmentation)とは [概要]
データ拡張 (Data Augmentation, データ増大) とは,機械学習の前処理として,「学習用データセット」の各データサンプルを,変形させたり組み合わた新データをたくさん増大(Augmentation)させることで,データセットの量と分布(variation)を拡げる処理である.とりわけ,コンピュータビジョン向けの画像のデータ拡張の処理では,元の各画像データをアフィン変換やカラー処理を行ったり,画像の部分領域のカット(cut)や削除(delete)・マスク化(mask),複数画像/複数領域の混合(mix)などを通じて,データ拡張を行うことが多い.
この記事では,画像変形や画像混合などのみを用いる「モデルフリーの画像のデータ拡張」の路線の各手法を,[Naveed et al., 2021] に沿った4分類形式(1.2節)にそってまとめていく.まず2節で最初に,データ拡張の背景と動機についてまとめる.3節では「単一画像からのデータ拡張」の「AlexNetから始った画像処理ベースの手法」(3.1節)と「CutOut 系の手法」(3.2節) を紹介する.4節では,「複数画像を用いたデータ拡張」の,「Mixup 系の手法」(4.1節)と「CutMix 系の手法」(4.2節)の手法を紹介する.
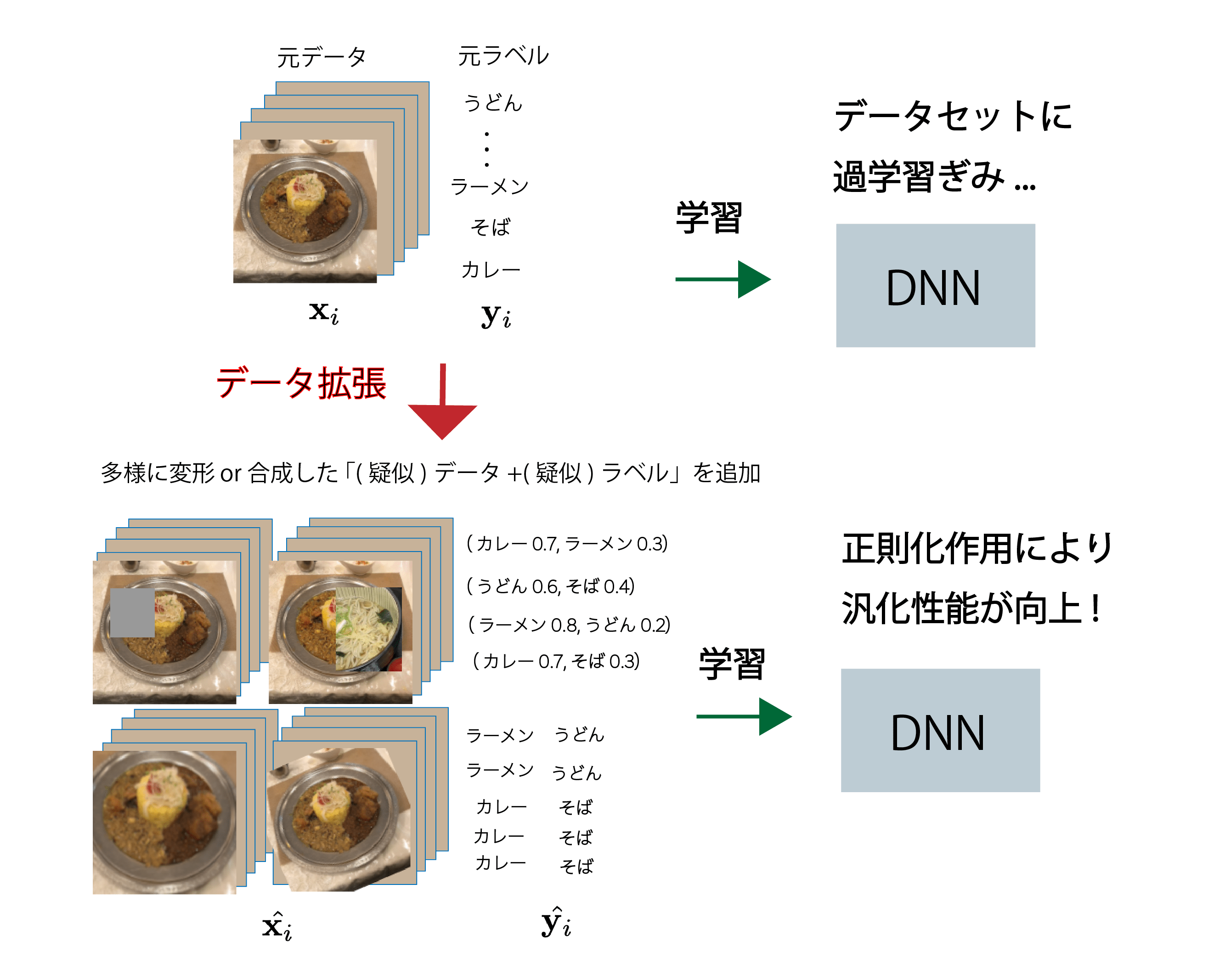
深層学習において,データ拡張(図1)を行うのは,CNNやTransformerなどの「大規模パラメータ深層学習DNN」の過学習を防ぎたいことが主な動機である(2節で詳しく).大量のパラメータを備えているせいで,少ないデータだけでDNNを学習すると,容易に過学習してしまう.モデルフリーのデータ拡張であれば,前処理として簡単なデータの変形処理や合成などの,「最小限の努力(計算コスト)」のみで,学習データとラベルを水増することができ,その拡張されたデータセットでDNNの過学習を低減できる(図1).その上,データセットに含まれている画像群の多様性(例:視点,物体の大きさ,コントラストなど)を増やすこともできるので,正則化の効果も得られて,DNNの汎化性能向上も望める (2節).
※ Data Augmentationは,本来はそのまま「データ増大」と翻訳して呼ぶほうが,増大(Augmentation)の意味どおりなので好ましい.ただ,既に日本語圏で定着したデータ拡張で呼ぶことにする.Expansionだと「(元の量を)拡大(して大きくなる)」である.各画像を増大させた結果,データセットの拡張が達成される.
その発展として,学習済みの深層生成モデルや,画像のスタイル変換モデルなどを用いて画像を生成する,「モデルベースのデータ拡張」も可能であるが,そちらの路線は(さしあたって)この記事の対象外として,モデルフリーの手法のみ,この記事では取りあげたい.
※ モデルベース手法は,この手法の5節以降にのちに追加するか,もしくはサイト中ではとりあげず,書籍や講義などの有料媒体でのみとりあげたい.
1.1 記事の構成
- 1.2節
- 1.2.1 モデルベース v.s モデルフリー
- 1.2.2 モデルフリー画像向けデータ拡張の4分類
- 2節 データ拡張の背景と動機
- 2.1 過学習しやすい画像向け大規模DNN
- 2.2 画像のバリエーションとの関係
- 2.3 いつモデルフリー or モデルベース?
- 3節 単一画像からのデータ拡張
- 3.1 画像処理系の手法
- 3.2 CutOut系の手法
- 4節 複数画像からのデータ拡張
- 3.1 Mixup系の手法
- 3.2 CutMix系の手法
- 5節 まとめ
1.2 「画像のデータ拡張」の分類
1.2.1 モデルベース v.s. モデルフリー
当初のデータ拡張は,AlexNetやInceptionNetで導入された「画像処理」を用いてデータセット画像を水増しする,(1) モデルフリーの手法が中心であった.それに対して,深層生成モデルが発展して以降は,学習済み生成モデルで生成したデータを水増しデータに用いる(2) モデルベース手法も,登場して研究されていった.
この記事では,前者の「モデルベースの手法」にフォーカスして,3節,4節で紹介していく
1.2.2 モデルフリー画像向けデータ拡張の4分類

代表的な「モデルフリー手法」は,2つの分類軸の掛け合わせにより,以下の表のような, (2 x 2) = 4パターンに分類できる ([Naveed et al., 2021] の分類にならったもの):
| 全体(Global)を一括処理 | 局所(Local)領域を切り出し(Cut) | |
| 単一画像の変換 | (a) 画像処理ベース (3.1節) | (b) CutOut系 (3.2節) |
| 複数画像の混合(Mix) | (c) Mixup 系 (4.1節) | (d) CutMix系 (4.2節) |
2. データ拡張の背景と動機
2.1 過学習しやすい画像向け大規模DNN
大規模なDNNの, CNNやTransformerは,いずれも「大量の学習データをフィットさせる」モデルである.よって,アノテーション付きのデータセットを用いて学習しようとすると,「膨大な数のパラメータ > (高次元な)画像データ数」の関係になってしまい,過学習してしまいやすい(図1. 上半分).
そこで,新規の画像データ収集と正解のアノテーションを避けるために,アノテーションは追加せずに,画像データだけ変形させることになる
ちなみに,自然言語処理の場合だと,各トークンを埋め込み層で512次元くらいのベクトルにした単位で,Transformerに入力させることが多い.各ピクセルが周辺と連続的に関連する「画像データ」と異なり,文では全体の意味の整合性を保持しながらデータ拡張をする必要があるので,名詞や動詞の入れ替えや,(BERT/GPTなど自己教師有り学習での)単語単位でのマスク化によるデータ拡張がメインとなる
2.2 画像のバリエーションとの関係
画像DNNの汎用性を高めるためには,2.1節で述べた「過学習の対策」以外にも,「画像のバリエーション(variation)」を広めに確保したデータセットを用いてCNN(やVision Transformer)を学習することが好ましい.
この記事で主に取りあげている「物体画像(object image)」においては,たとえば以下のような画像のバリエーションが豊富であるほど,汎化性能の高い画像認識モデルが学習できる:
- 照明や色の変化.
- 物体の歪み,姿勢変化,遮蔽ぐあい.
- 背景の異質度あい.
- 視点の変化.
- 物体の写っているスケールの違い
- 以上にあげたものの,それぞれの組み合わせの違い
(1)このなかでは,各層で「不変性 (invariance)」を獲得しているものもある.たとえばCNNの場合,(ローカル)プーリング層を通じて「局所平行移動・局所歪みへの不変性」を獲得していたり,入力層でもZCN正規化などを通じて「色・照明への不変性」を獲得している.よって,データセット中の画像では,これらのバリエーションはあまり豊富でなくとも,画像認識性能の良いCNNやViTなどを学習できる.
(2)一方で,多用な学習用の物体画像において,データ拡張なしに,「新しい画像の収集」でバリエーションの豊富さを確保せざるを得ないものには,「物体の3D(視点)の視点の変化」や,「ヒトや動物の姿勢の変化」などの視点・姿勢の変化や,「道具,自動車や建物などの,物体のテクスチャの変化」や「ヒトの顔や服装の変化」などがあげられる.
2.3 いつモデルフリー or モデルベース?
このあと3節,4節で紹介するデータ拡張手法では,「新たに物体画像収集しなくとも,(簡単な処理の)画像変換で疑似的にバリエーションを増やすことができる」範囲で,画像のバリエーションを水増しする手法である.つまり,モデルフリーのデータ拡張(3,4節)で,ある程度事足りる.ただし,上述(1)で述べたように,CNNやVision Transformerはモデル内でも,いくつか不変性を獲得するので,それらに対応するバリエーションを増やす画像の拡張は,あまり必要がない(増やしても,どうせい不変性によって吸収される).
その反面,上述の(2)パターンでは(2次元的)画像処理だけでは,水増ししづらいゆえ,5節以降のような,モデルベースのデータ拡張を用いてしてか,学習画像の水増しはできないと言える.
3D画像生成モデルが登場する前の時代からも,CGモデルのレンダリング結果を学習画像として活用する「合成データからの学習(Learning by Synthesis)」を活用したデータ拡張は,行われていた.ただ,現在では深層生成モデルによって,3D変化も加味しながら,リアルな物体画像生成までできてしまうので,その「フォトリアルな」生成画像をデータ拡張に使うことが普通になってきている.
※ 今でも,CGレンダリングデータを同時に使ってもよいが,そのフォトリアル度が,「実画像データに混ぜてよい質」に達しているか次第だと思う
3. 単一画像からのデータ拡張
3.1 画像処理ベースのデータ拡張

AlexNetで「物体認識むけCNN学習での,画像のデータ拡張の使用」の提案を皮切りに,CNNバックボーンが順に改良されるたびに,少しずつ「画像処理・画像変換操作によるデータ拡張(図3)」が試されていく.
それは,各種のアフィン変換 (回転,平行移動,スケーリング(拡大・縮小)など)や,画像の左右反転(フリップ)などの,「モデルフリーな(計算コストの低い)画像変換」のみを使用して,画像のデータ拡張を行う路線である.
ImageNetの物体画像を用いて,物体認識のCNNへクラス識別器を学習することが始った時期に,まず最初にAlexNetの研究において,画像のデータ拡張の原型が提案された.AlexNetでは,「元画像 [256 x 256]のサイズを フリップ→ [224 x 224] のサイズでランダムにクロップ」することにより,(平行移動で少しずらした)大量のデータ拡張画像を手に入れる「フリップ + クロップによるデータ拡張」が行われた.更に「輝度の変更(≒ 照明やコントラストの変化)」も提案され,その後によく使用されていった.
「VGGNetでのデータ拡張」では,元画像を[256, 256]だけでなく,スケーリングさせて物体を大きく写るようにした [384,384]からもクロップする「データ拡張のマルチスケール化」も行われ,マルチスケール認識への対応もはかられるようになった.
関連記事:VGGNet: 初期の定番CNN (3.3節)
また,物体検出むけでも,初期の定番手法であるFaster R-CNN や YOLO・SSDでも,データ拡張は導入された.画像のフリップや,平行移動,に加え、物体領域の回転やシアーで,微小な歪みを加えることも好まれるようになる.また,物体検出でも「複数スケールへの対応」が大きな目的となるSSDの提案以降は,拡大縮小もデータ拡張によく使われることになる.
3.2 CutOut系のデータ拡張
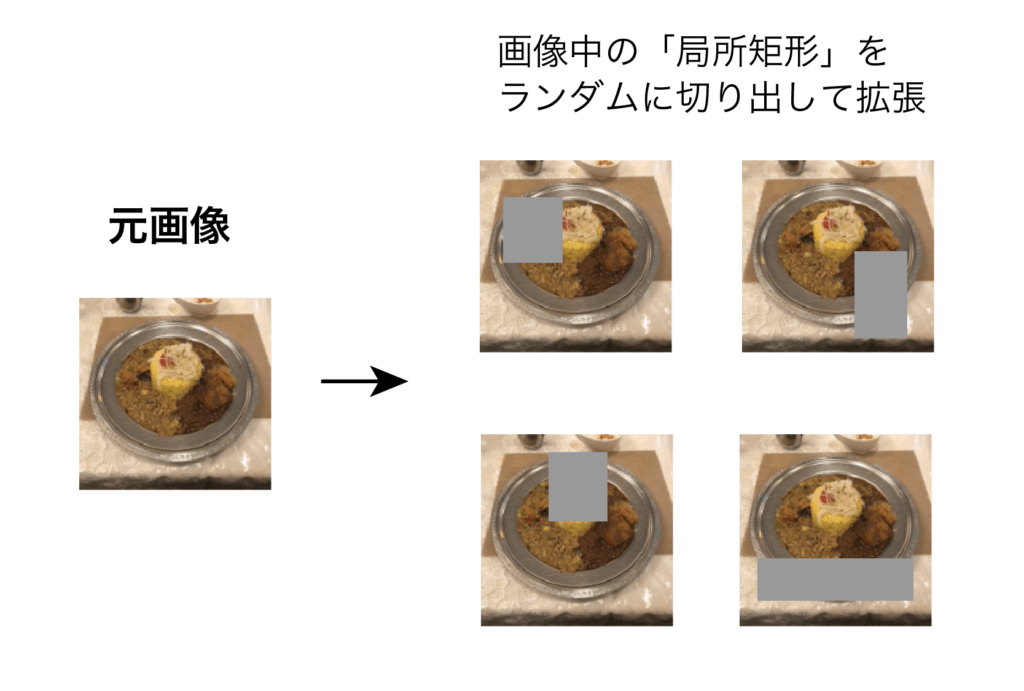
Cutout [DeVries and Taylor, 2017] の研究では,物体認識において,CIFAR-10 データセットの各画像から,一部分の矩形をランダムに削除(cut out)する形式の,画像データ拡張が提案された(図4).Cutoutでは,ランダムなマスクが入力データにかかることで,クラス識別(の出力ラベル)に対して重要な特徴パターンを学習しやすくなる.
これは一部分をクロップして削除していることにも相当しており,Cutoutした画像データのおかげで,部分遮蔽や部分欠損にたいする頑健性が期待できる.
※ BERT/GPTなどでの,自己教師有り学習におけるランダムマスク化と,動機は近い.
また,Cutout系の手法は,汎用性向上の文脈で考えると,部分領域的のドロップアウトとも取れる手法である.(データセット全体の)各入力画像からランダムに領域を削除することで,データを疑似的に増やし,正則化の効果を狙っているといえる.
Hide-and-Seek [Sing and Lee, 2017]では,このCutout系手法が,(弱教師有り)物体検出とアクション検出むけに応用された.
4. 複数画像からのデータ拡張
物体認識データセットの,画像データを$x \in \mathbb{R}^{W \times H \times C}$とし,そのクラスラベルを$y$とする.ここでは,2つの学習サンプル $(x_A, y_A)$と$(x_B, y_B)$を,(1)全体で合成する手法(4.2 Mixup系),(2)局所のバウンディングボックスで合成(4.2節 CutMix系)
4.1 Mixup系のデータ拡張
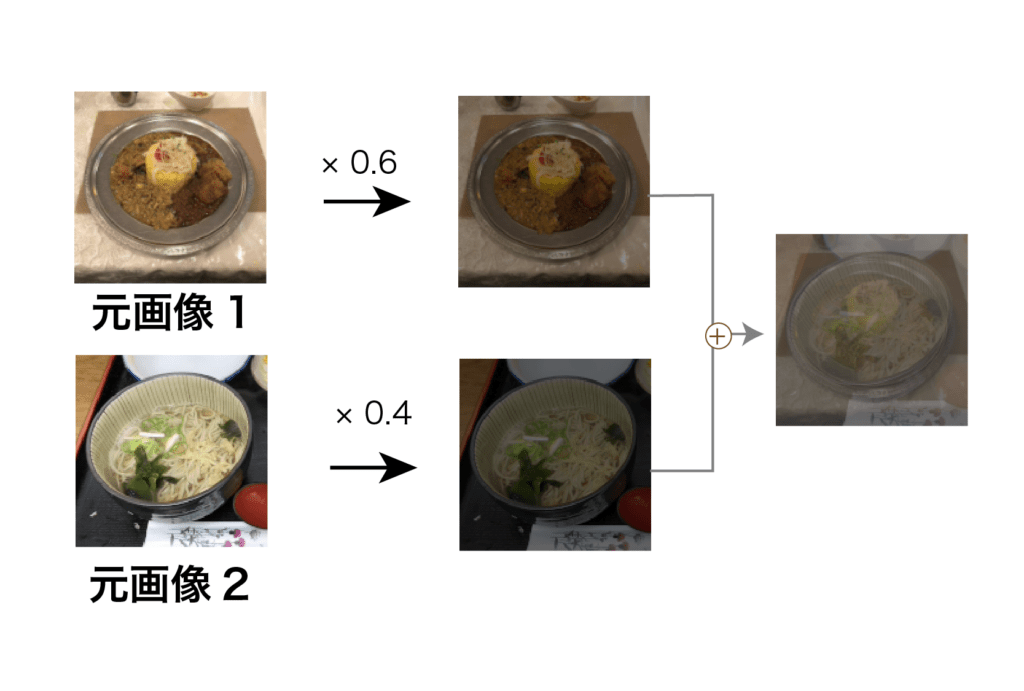
Mixup [Zhang et al., 2018] では,データセット内からランダムに選んだ学習サンプル $(x_A, y_A)$と$(x_B, y_B)$ から,2枚の画像とラベルを,それぞれミックス度$\lambda$で合成した,新画像$\hat{x} $を作成して拡張データとして用いる手法が提案された (図5)
要は,下記の式と(図5)のように,線形に$\lambda$ 対 $1- \lambda$で(線形)合成する,シンプルな手法である:
\begin{align}
\hat{x} &= \lambda x_A + (1-\lambda) x_B \\
\hat{y} &= \lambda y_A + (1-\lambda) y_B
\end{align}
Mixup の提案研究 [Zhang et al., 2018]では,(3節の各手法などと同様に)CIFAR-10やImageNetデータセットでの,ResNet, ResNeXtを用いた物体認識の実験が行われ,Mixupの有効性が示された.CIFAR-10での実験では,ラベル平滑化など,他の正則化路線との比較も行われている(論文中 Table. 5).
4.2 CutMix系のデータ拡張お

CutMix [Yun et al., 2019]では,Mixupを「局所領域混合化」したような手法で,「複数画像合成(Mixup)+Cutout化」したものである.
従来の手法(3.2節 Cutoutや4.1節Mixup)では作れなかった,リアルな2クラス合成画像をつくれるゆえ,従来手法より更に頑健なデータ拡張およびそれによる正則化を期待できる.
※ 図2のテーブルも見返すと,これまでの4手法(3.1,3.2節 4.1,4.2節)の違いがわかる.
CutMixでは,学習サンプル $(x_A, y_A)$と$(x_B, y_B)$ から,画像については局所領域のバウンディングボックスのマスク $\bm{M}$ を用いてパッチ前景+パッチ背景の合成を2クラス画像間で行う(Mixupのような画像全体単位での線形合成は行わないのがポイント).また,ラベル $y$ については,Mixupと同じ方式で,混合率$\lambda$によるmixを行う:
\begin{align}
\hat{x} &= \bm{M} \odot x_A + (\bm{1}-\bm{M}) \odot x_B \\
\hat{y} &= \lambda y_B + (1-\lambda) y_B
\end{align}
これにより,Cutout + Mixupのもつ「画像のカットと合成」の効果と,Mixupのもつ「ラベルの混合の効果」が期待できる.
CutMix [Yun et al., 2019] 論文中のFigure 1 では,拡張画像の例として「コーギー犬画像の顔部分が,猫の顔にさし変わった」CutMix済み画像と,従来手法のMixupとCutoutによる混合画像と比較がされている.
このFigure.1 での比較を見てもわかるように,下手に$\lambda$で線形Mixupはしないし,顔だけCutuoutして黒塗りもされない「CutMixでの拡張画像」は,クラス混合やクラス間境界(曖昧性)を,Mixup/Cutoutよりはよく捉えられた拡張画像を手軽につくれる.従って,入力画像の崩れ(corruption)や,(Out-of-Distribution; OOD)の性能の向上も期待できるわけである.
論文[Yun et al., 2019] 中の実験では,ImageNetでの物体認識だけでなく,ImageNetとPascal VOC を用いた物体検出でも,従来手法(Cutout/Mixup)と比べての性能向上が確認できた.
5. まとめ
モデルフリーの「画像のデータ拡張」を,図2の4分類に従って,順に初期提案研究を紹介した.
その4分類のうち,単一画像でのデータ拡張(3節)と,複数画像(2枚の合成)でのデータ拡張(4節)を紹介し,CutoutとMixupのいいところどりな「CutMix(4.2)」の路線が,モデルフリー手法の(目下の)到達点になっていることを示した.
この記事では述べていないが,その後は,物体認識だけではなく,物体検出に画像キャプション生成など,他の(物体ラベルを使用する)画像認識系タスクにおいても,CutoutやMixupにCutMix, などのデータ拡張は,使用されるようになっている.
関連書籍
- 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之,講談社,2022.
- 11.2 データ拡張 (p254)
- Probabilistic Machine Learning: An Introduction, Kevin Patrick Murphy , MIT Press, 2022.
- 19.1 Data Augmentation
- 物体・画像認識と時系列データ処理入門 [TensorFlow2/PyTorch対応第2版] NumPy/TensorFlow2(Keras)/PyTorchによる実装ディープラーニング,チームカルポ,秀和システム,2022
- 7.2 (p426) (CIFAR-10で基礎的なデータ拡張を試す節)
- 物体検出とGAN、オートエンコーダー、画像処理入門 PyTorch/TensorFlow2による発展的・実装ディープラーニング,チームカルポ,秀和システム,2022
References
- [DeVries and Taylor, 2017] DeVries Terrance, and Taylor W. Graham,. Improved regular- ization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- [Naveed et al., 2021] Naveed, H., Anwar, S., Hayat, M., Javed, K., & Mian, A. (2021). Survey: Image mixing and deleting for data augmentation. arXiv preprint arXiv:2106.07085.
- [Sing and Lee, 2017] Krishna Kumar Singh and Yong Jae Lee. Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 3544–3553. IEEE, 2017.
- [Yun et al., 2019] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, Y. Yoo, Cutmix: Regu- larization strategy to train strong classifiers with localizable features. In CVPR, 2019.
- [Zhang et al., 2018] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. In ICLR, 2018.
参照外部リンク
- SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向 中山英樹,幡谷龍一郎