
1. 概要
画像認識 (Image Recognition) とは,入力画像に対して,アルゴリズムや機械学習モデルやディープラーニング済みのネットワーク等を用い,その画像内に写っている人・モノ・背景について,種類・属性値などを(自動で)パターン認識するという「コンピュータビジョン分野の代表的問題設定の1つ」である.
この記事では,画像認識の概要説明(1.1)と振返り(1.2)を行なった後に,2節で「ディープラーニングで解かれるコンピュータビジョンの画像認識タスクの代表例」の概要を短くまとめ「それらタスクのトップ親記事」へとリンクする:
- 2.1節 物体認識
- 2.2節 物体検出
- 2.3節 セマンティックセグメンテーション(意味的分割)
- 2.4節 インスタンスセグメンテーション(実例分割)
- 2.5節 人物姿勢推定
ただし,この記事は,用語Wikiで紹介しているディープラーニング時代の代表的な画像認識タスクについて,簡潔に列挙した「まとめ記事」であるゆえ,教科書で出てくるような「代表的かつ典型的なディープラーニングの画像認識タスク」のみ取り上げているため,「それ以外の画像認識タスク」は,この記事には登場しない点には,注意していただきたい.(例:「顔認識」や「テキスト認識」など).
つまりは,「網羅的に画像認識を説明する記事ではない」という点を念頭において,記事を読んでもらえると助かる.
1.1 画像認識 (image recognition) の概要

画像認識では,画像に写る対象の様々な要素を,ディープニューラルネットワークなどの認識系モデルを用いて推定する (図0).とりわけ,画像中の「物体・人物・背景」の領域検出や,意味(クラスの)認識に,シーン中の意味ごとの領域分割(セマンティックセグメンテーションとインスタンスセグメンテーション)が,画像認識における基本的な興味となる.
また,人物の認識をより深める場合には,顔認識であったり,(私が博士課程の頃に興味が高かった) 人物姿勢推定や,服装・スタイルなどの認識といった方向性が出てくる.(本記事2節では取り上げないが),人や物体の属性(attribute)を認識したり(例:顔認識 , 服装・スタイル認識,色,体型の認識など),「画像中の文字・数字の認識(=テキスト認識)」なども,画像認識の典型的な,サブジャンルである.
1.2 ディープラーニング定着以前の画像認識
機械学習が発達していなかった古い時代では,例えば,『エッジ検出(例:Cannyエッジ検出器)や,カラーヒストグラム抽出などで「特徴画像化」したのちに閾値判定処理をつくる』ことや.『テンプレートマッチング等でパターン図形を抽出する』などの,「(非機械学習な手法による)ルールベースの画像認識処理」が主に行われていた.
次に,家庭用PC(パーソナルコンピュータ)の計算資源が増え,CPUでの高速計算が可能になってて行くとともに,2000年~2005年ごろになると「画像特徴量(HOG/SIFTなど) +機械学習(SVM, Random Forestなど)」の組み合わせで実現する,SIFT系キーポイント特徴の集約による画像認識が実現したり,「Haar-like画像特徴+Adaboost」や,「HOG+SVM」での「動画の各フレーム画像に対する 顔・人物・物体検出」なども実現し始めた.
以下の,2つの「おすすめ書籍まとめ記事」でも紹介している「画像認識(機械学習プロフェッショナルシリーズ) (2018) 」だと,これらの2005~2015年頃のディープラーニング以前の画像認識の内容も学べる.
また,情報幾何系の工夫なども用いた「高次の画像特徴 (例:Bag-of-Visual Wordsや,その後のFisher Vectorなど)」の登場により,それまで数10クラス程度のクラス数までで行なっていた画像認識・画像検索が,大量のクラスを分類対象にできるようになり,imageNetデータセット(2010年~2017年)を用いた「画像認識コンペティション時代」へと突入していき,その頃にディープラーニングのブームや普及・発展も開始して,初期のCNN(バックボーン)の成功例としてAlexNetやVGGNetなどが登場し,ディープラーニングが主流の時代へと徐々に突入していった(2011年~2013,2014年頃)
2. 画像認識の代表的タスク
既に述べた,コンピュータビジョンでの「代表的な画像認識のタスク」を2節では概要とともに列挙していく.
画像の認識・理解系のタスクを紹介するので,入出力が逆方向である深層生成モデルを用いた「画像生成タスク」や,「画像変換系タスク(pix2pixなど)」は,この記事中では取り扱わない.
また,この記事は1枚画像の認識である画像認識の記事であり,動画認識(video recognition)は別物と
2.1 物体認識 (画像分類の1種)
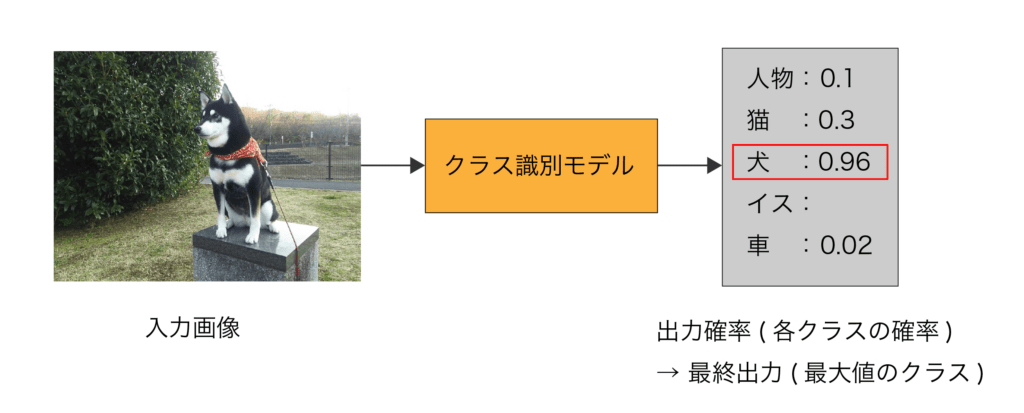
物体認識 (Object Recognition)とは,中央に注目物体が1つ映っている物体中心画像を入力として,機械学習モデルを用いて,画像中の注目物体のクラスカテゴリーの識別を行うコンピュータビジョン・画像認識の代表的問題である.物体認識の問題は,物体中心 (Object-centric)な画像1枚を入力として,対象となる「N個の物体クラス」から1つだけ該当するクラスを選び出す問題である (図1).機械学習・パターン認識の目線で言い換えると,「物体中心画像1枚を入力として,Nクラスの画像分類を行う」問題である.
かつての研究では,Pascal VOCデータセットなどをベンチマークとして,手作り特徴量 + 中規模機械学習モデル(SVMやBoosting/RandomForestなど) で取組まれていた問題であった.それが,ディープラーニングとImageNetデータセットの登場以降は,物体中心画像を入力としてCNN(畳み込みニューラルネットワーク)で実現されることが標準的である.また,近年(2021~2022年以降)では,CNNの変わりに,大規模なVision Transformerを使用する研究例もでてきた.
2.2 物体検出

物体検出 (Object Detection)とは,画像の入力に対して,画像中に映っている各物体領域のバウンディングボックスを検出し,その物体のクラス識別も行う,画像認識の重要な問題である.また,物体中心 (Object-centric)な処理を行うための前処理(矩形領域抽出)でもあるので,その意味でも,非常に重要かつ本質的な問題の1つである
物体検出は,入力画像において,各物体インスタンスの(1) 関心領域(ROI)を矩形で囲ったバウンディングボックスを検出(detect)し,その (2) 物体ROIの意味的な物体クラスの識別も行う.初期の代表的なCNNとしては,アンカーあり2ステージ型のFast R-CNNや,アンカーあり1ステージ型のSSD, YOLO v2などがあげられる.いずれも,密に画像座標 or 特徴マップ座標上に配置したアンカーボックス群からの,「クラス分類 + Bounding Box回帰」を「2ステージに分割して行う or 1ステージで一気に行う」 手法である.
また,Transformer登場後は,CNN+Transformer-Decoderを用いて物体検出モデルを学習するDETR (DEtection TRansformer)や,(DETRと同じく)疎な少数物体クエリ群から推定を行うSparse-CNNなども登場し,よく研究されるようになっている.
2.3 セマンティックセグメンテーション(意味的分割)

セマンティックセグメンテーション (Semantic Segmentation, 意味的分割)とは,シーン画像に対して,画素ごとに独立して意味的な(Semantic)クラス識別を行い,画像上の領域分割をおこなう問題である.画像Encoder-Decoderを用いた高精度な深層学習手法が立て続けに登場して以降,ブレイクスルーが起こった技術である.FCNやU-NetにDeepLabにPSPNetなどが,初期の代表的なCNNである.
各画素の織別に用いるクラスとしては,「道路」「人」「自転車」や,「空」「海」「建物」などの,「おおまかな意味的な単位」を用いる.2010年代に入って以降の,自動運転研究の開始に伴い,取り組む研究者が増えた問題でもある(例:SegNet など).また,医用画像処理の領域分割用途などでも実用性が高いゆえ,深層学習の発展に伴い応用事例が増えた問題と言える(例 U-Netなど).
2.4 インスタンスセグメンテーション(実例的分割)

インスタンスセグメンテーション (Instance Segmentation), 実例分割 とは,画像上やRGB-D画像に写っている「物体クラスの実例 (Instance)」の前景マスクを,各インスタンスごとに区別して検出する問題である.初期のCNNとしては,DeepMaskとSharpMask や 代表的手法となったMask R-CNNなどがあげられる.
図4では,複数物体・複数クラス画像が映る入力画像に対する,以下の表中の4つの問題において,出力の違いを描画し,それぞれのタスクを比較できるようにしてある:
同じ画素毎のクラス識別の中において,2個以上の同一クラスの複数インスタンスが写っている際に,セマンティックセグメンテーションでは,インスタンスの違いは区別せず「意味クラスの識別」だけをおこなう(図1-c).従って,図1-c のように,2つの「dog」インスタンス同士が物体間遮蔽している場合だと,それらの境界は判別できず,1領域につながった状態で各領域が推定される.
2.5 人物姿勢推定

古典手法の記事:古典的な人物姿勢推定[non-deep learning手法]
画像からの人物姿勢推定 (Human Pose Estimation)とは,入力画像中の各人物に対して,画像上のキーポイントや,それらの点ペアを結んだ2次元ボーンを,その人物の姿勢の現在の状態として,推定する問題のことである.OpenPoseなどが,代表的な人物姿勢推定向けのCNNである.
図1のように,首から下の「四肢と体幹の2Dボーンの人物姿勢 (Articulation)」を推定することが,2D人物姿勢推定問題の主目的である.頭部や手先・足先,顔や目・鼻などについては,1点もしくは数点で簡易的に表現する.そして,その他に,体幹部と腕・足の各関節キーポイントの推定も行う.
3. まとめ
以上,ディープラーニング以前の画像認識の歴史的概要(1節)を述べたあと,ディープラーニング時代の代表的な画像認識タスク(2節)を列挙した.
「全体を俯瞰的にみつめなおしやすい記事」であるので,このページを定期的に眺めることをおすすめしておきたい.
関連書籍
- Pythonで学ぶ画像認識 (機械学習実践シリーズ) 【📖紹介記事】, 田村 雅人, 中村 克行, インプレス, 2023.
- 画像認識(機械学習プロフェッショナルシリーズ),原田達也,講談社,2017.
- 物体検出とGAN、オートエンコーダー、画像処理入門 PyTorch/TensorFlow2による発展的・実装ディープラーニング チーム・カルポ、秀和システム,2021.
- 2章: SSDの詳しい実装方法.