
1. Faster R-CNNの 領域提案ネットワーク(Region Proposal Network, RPN) とは【概要】
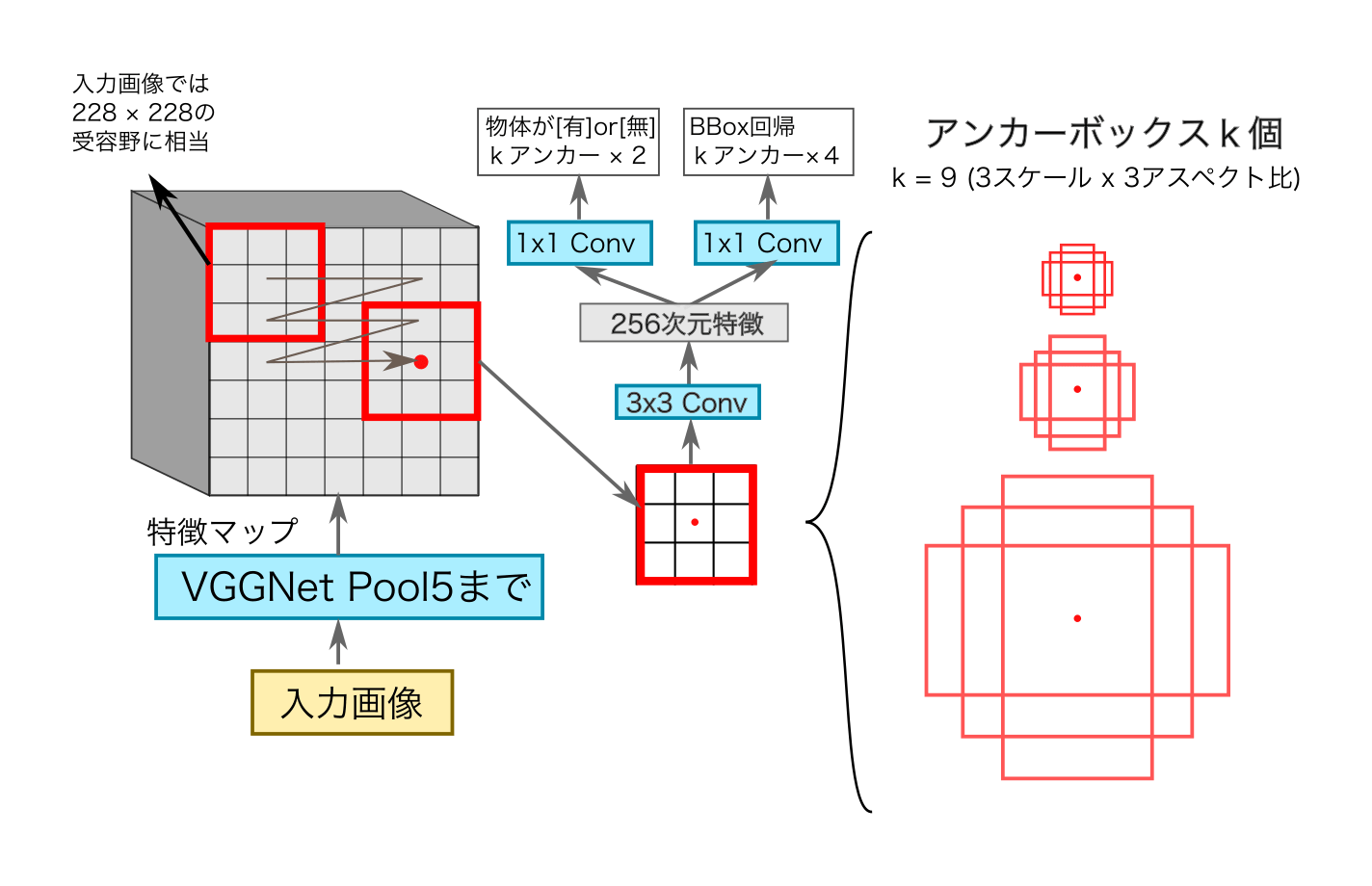
領域提案ネットワーク(Region Proposal Network, RPN) とは,Faster R-CNNや Mask R-CNN などの「アンカーあり2ステージ型物体検出ネットワーク」において,1ステージ目を担当し,物体ROI矩形の候補である領域提案(region proposal) を検出しておく「事前のスクリーニング(仕分け)」を担当する物体検出CNNである(図1).
この記事は,Faster R-CNNのうち「RPN部分」のみを説明している「Faster R-CNNの子記事」である.Faster R-CNNの全体像は,以下の親記事を参考のこと:
RPNは「Faster R-CNN やMask R-CNN [He et al., 2017] 等の,1st ステージ部分に使用する物体検出CNN」である.当初はFaster R-CNNの論文で提案されたので.Faster R-CNNの物体検出 目的であったが,その後は「Mask R-CNNのような2ステージ型CNNでのインスタンスセグメンテーションや人物姿勢推定」においてもRPNが活用される展開になる.
1.1 RPNによる「候補物体の検出」とは?



Faster R-CNNの前身2手法「R-CNN (図2)とFast R-CNN (図3)」では,non-deep learaningな任意物体候補検出手法「Selective Search [Uijlings et al., 2013]」を,前段の候補検出部分に用いていた.
それに対して,「Fast R-CNN候補検出部分を,初めてCNN化できたもの」が,領域提案ネットワーク(もといFaster R-CNN) である.Faster R-CNN のRPN (図4 左:前半ステージ)では.VGGやFeature Pyramid Networks などのCNNバックボーンに学習しておいた「領域候補(region proposal)のROI矩形」を検出する.
また,この直前の時期に古典的な物体検出の手法から拡張するかたちで,non-deep learaning提案・研究されはじめていた「Nクラスの物体どれも1つの検出モデルで検出しよう」という「Objectness 検出器 [Cheng et al., 2014など]」ともRPNは同じ概念・目的であると,俯瞰できる.
Faster R-CNN や,Mask R-CNNなどのRPNが検出する領域提案のROI群は,(COCOデータセットやOpen Imagesなどの)物体検出データセット中のNクラス物体を全ての学習したものとなる.
2. 領域提案ネットワークの詳細
2節ではRPNの処理の詳細 (図5)と,そこで重要なアンカーボックスについて見ていく.
2.1節では,Faster R-CNNのRPNで(1stステージのCNN化に伴い)導入された,「アンカーボックスを用いた(マルチスケール)検出」の処理手順・目的をみる.次に2.2節では「RPNの学習に用いる損失関数の中身を見る」ことを行ない,それにより「(1.1節で述べたように )RPNは事前スクリーニングのための任意物体検出ネットワークを学習していること」を確認してもらう.
2.1 アンカーボックスを用いた,効率のよいマルチスケール検出
RPNでは「アンカーボックス群を用いた,効率的なマルチスケール検出」が導入された (図1 中央部と右側).RPNでは,(元画像よりは)大きな幅でスライドでスライディングウィンドウしていき,特徴マップ上の各アンカー点の位置で,「$k = 9$個の窓スケール×アスペクト比」でプーリングした特徴をもとに,物体検出する.(以下のアンカーボックスの記事でも書いているように),このアンカーボックスの導入により, 少ない回数でマルチスケール検出を行ない,そのあと回帰ヘッドでROI矩形を微調整することが可能となる.
2.1.1 RPNによる,入力画像からの候補検出手順
領域提案ネットワーク(図1)では,(Faster-CNNなどの1ステージ目として)以下の手順で処理を行う:
RPNの処理手順
- まずは入力画像を,VGG や Feature Pyramid Networks などのCNNバックボーンを用いて,畳み込んでいき「特徴マップ」を作成.(図1 左側)
- その特徴マップ上で,$3 \times 3$セルの窓で,スライディングウィンドウを行う(図1 左上)
元のFaster R-CNN の論文[Ren et al., 2015] では,入力画像の3スケール(128 x 128, 256 x 256, 512 x 512) と 3アスペクト比(w+hの値をそれぞれ 1:1, 1:2, 2:1に分配したもの)の組み合わせの合計 $k = 9$個のアンカーボックスを,スライディングウィンドウ処理用に用意していた (図1 右側).
この結果,各スライディングウィンドウ窓の位置に対して,$(2+k)$チャンネルのマップが出力され,それらをもとにNMS処理をおこなった後,最終的な(2ndステージ向けの)領域候補(region proposal)が確定する.
2.1.2 アンカーボックス導入の利点
アンカーボックスの導入は,領域提案ネットワーク(RPN)に,以下の長所をもたらした:
- 効率・高速化:
- 「セル窓(3 x 3)上の特徴から,$k$個分の特徴をいっぺんに1ヘッドで出力する設計にした.
- これにより,特徴抽出層が$k$ボックス分共有されており,処理が効率化されている.
- 物体サイズ多様性への対応:
- 各窓位置において,スケール・アスペクト比が異なる物体同士を,複数個検出できる.
- 物体内,物体間遮蔽への対応:
- 領域提案のアンカーボックスを回帰させて修正,また,複数クラス間での見え方の関係性を学習できる.
- よって,「馬に乗った人」のような別クラス間での遮蔽と,「上半身しか写っていない人」のようなインスタンス内の遮蔽(※ VOC 2007で言う「truncatedラベル」) ,の双方に強いモデルを学習できる(元論文 Figure 1 右の,検出例画像などを参照).
各[3 x 3] 窓内のアンカーk個検出処理する際に(図1 左側),その [3 x 3] x C の特徴マップ入力に対して,Fast R-CNN [Girshick, 2015] のように「クラス識別 + bbox回帰」で物体検出の評価を行うネットワーク(図1中央)を設計したい.ここで(ROI Poolingと同様に)ROI矩形中心点の「アンカー点 (図1 のROI/アンカー矩形内の中心赤点)」の位置を,「①入力画像の空間座標系」と「②CNN特徴マップの空間座標系」のあいだで対応付けしておく.そして,入力画像における「領域提案のスケール and アスペクト比」の事前分布として,アンカーボックス $k = 9$種類を用意する.
これにより,「特徴マップ上をスライディングウィンドウ中に,最小限の回数のみしか検出ヘッド処理(図1, 真ん中)をしないで済む」計算効率化のメリットがうまれ, 後処理の2ndステージでも,1stステージのRPNが検出した「(クラスは未確定の)物体」の領域提案ROI矩形のみを相手にすればよくなる.
その窓位置のROI内の特徴マップをもとに「(1)その領域候補物体が,アンカーボックス内に存在するかどうかのObjectness識別」と「(2)アンカーボックスに対しての,正解の領域提案領域のBBox修正量回帰」を推定することを行う(図1).
2.2 RPNの損失関数
RPNは,Fast R-CNN (親記事Faster R-CNN: 2.1節) の方式と同じ,以下の合成損失関数で学習する:
\[ \mathcal{L}_{RPN} (\{p_i\},\{\bm{t}_i\}) = \frac{1}{N_{cls}}\mathcal{L}_{cls}(\tilde{p_i},p_i) + \lambda \frac{1}{N_{reg}} \sum_i \tilde{p_i} \mathcal{L}_{reg} (\tilde{\bm{t}_i},\bm{t}_i) \tag{3.1}\]
ここで,各変数は以下の変数を指している:
- $i$: バッチ内のアンカーボックスのインデックス.
- $p_i$: $i$番目アンカーボックスの物体らしさ(Objectness)確率 [1: 物体, 0: 背景]の正解値.
- $\tilde{p_i}$: $p_i$の予測値.
- $\bm{t}_i$: $i$番目アンカーボックスの修正量$(t_x,t_y,t_w,t_h)$の正解ベクトル (2.1節).
- $\tilde{\bm{t}_i}$: アンカーボックスの修正量の予測ベクトル.
1.1で述べた通りだが,「物体クラス (1) or 非物体 クラス(0)」の領域候補のスクリーニングを担当するのが領域提案ネットワークであるので,「学習データのNクラス全てをいっしょくたにした,物体らしさ(Objectness)クラス」を,[1: 物体, 0: 背景]のラベルに用いる.
また,RPNでは,(2.1節で述べた通りに)1つの正解物体領域に対して,[スケール数×アスペクト比] 個のアンカーボックスが紐づけされており,それら全(/アスペクト比の)アンカーボックス損失の合計」を計算する.
式(3.1)では,回帰ロス側$\mathcal{L}_{reg}$の損失関数としてsmooth L1 損失を用いる.$\mathcal{L}_{reg}$を物体らしさスコア$\tilde{p_i}$で重み付けしているので,ポジティブクラスにラベル付けされた「正解bbox」に対応するアンカー($\tilde{p_i} = 1$)にしか,損失を加えないようになっている.
References.
- [Cheng et al., 2014] Cheng, M. M., Zhang, Z., Lin, W. Y., & Torr, P. (2014). BING: Binarized normed gradients for objectness estimation at 300fps. In CVPR 2014.
- [Girshick et al., 2014] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
- [Girshick, 2015] Girshick, R. Fast r-cnn. In ICCV, 2015.
- [He et al., 2014] He K., Zhang X., Ren, S., and Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
- [He et al., 2017] K. He, G. Gkioxari, P. Doll ́ar, R. B. Girshick, Mask r-cnn, In ICCV, 2017.
- [Ren et al., 2015] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: towards real-time object detection with region proposal networks. In NIPS, 2015.
- [Uijlings et al., 2013] Uijlings, J. R., Van De Sande, K. E., Gevers, T., and Smeulders, A. W. Selective search for object recognition. International journal of computer vision, 104(2), 154–171.
- [Wang et al., 2013] X.Wang, M.Yang, S.Zhu, and Y.Lin. Regionlets for generic object detection. In ICCV, 2013.
- [Wu et al., 2020] Wu, X., Sahoo, D., & Hoi, S. C. (2020). Recent advances in deep learning for object detection. Neurocomputing, 396, 39-64.