
1. Mask R-CNN とは [概要]
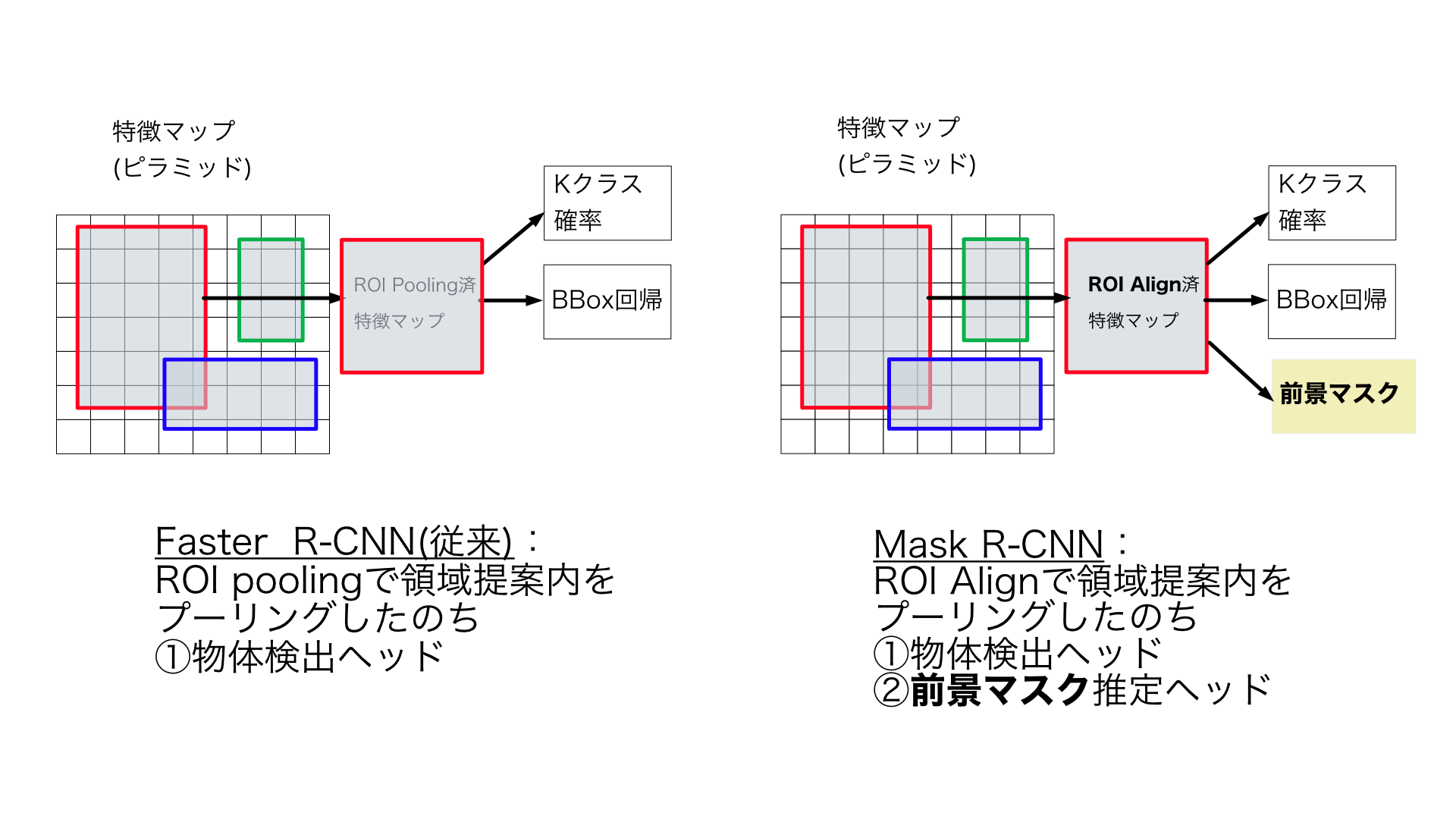
Mask R-CNN [He et al., 2017] は,インスタンスセグメンテーションの初期決定版となった.2ステージ型CNNである (図1 右).
Mask R-CNNは,「Faster R-CNN 構造の2ステージ型物体検出ネットワーク (図1左)」の2ステージ目に「前景マスク 推定ヘッド」を並列に追加し(図1右),ROI poolingを改良したROI Align(3.2節)を提案したものである.これにより2ndステージでの「マスク推定 & 物体検出」むけにつくる「ROI内の特徴マップ」の空間位置合わせが良くなり,正確なインスタンスセグメンテーションが(アンカーあり2ステージ型CNNで)可能になった.当時は「1stステージ領域提案ネットワークが出力した領域提案(Region Proposal)のROI内でしか,FCN 処理を行わない路線 (※)」が,他チームから提案中であり,その路線での最新手法としてMask R-CNN が登場した .
(※ 親記事インスタンスセグメンテーション の「3. Instance-aware FCN を用いた手法」を参照).
論文中の実験やgitihub上のコードでは,COCOデータセットでのインスタンスセグメンテーション実験結果が,実用的なレベルに近づき始めた上に,解き方もシンプルでわかりやすく発展・応用手法をつくりやすいので,その後のインスタンスセグメンテーション(やマルチタスクヘッド画像認識)の,初期の決定版的手法となった.
Mask R-CNNは,2017年当時のFAIR (Facebook AI Research)に所属していた 物体認識・物体検出のスター著者陣による有名な研究でもあり,「Faster R-CNNのシンプルなマルチヘッド化)」でありながらも,初めて高精度なインスタンスセグメンテーションを実現し,ICCV2017のbest paperを受賞し,その後の画像認識研究に大きな影響を与えた.
また,(この意義・存在を見逃されがちであるが) Mask R-CNNの論文は,「人物姿勢推定などの2Dキーポイントのヘッド」を追加して,(特に人物の)キーポイント推定もCOCOデータセットから同時に学習することも提案した(4節).これにより,Mask R-CNNが登場した2017年以降の「物体認識やセマンティックセグメンテーションだけでなく,(人物姿勢推定などの)キーポイント推定,マルチタスクヘッド学習」などの,全体的流れをMask R-CNNが大きく変える事になったので,この観点からもMask R-CNNは重要な研究・技術なのである.そこで4.1節では,管理人自身や当時所属していた慶應大 青木研究室の専門でもあった「3D人物形状モデルとその人物姿勢推定への応用」の目線も含めて,「人物姿勢推定(&人物形状推定)への,Mask R-CNN の意義や影響度」を振り返っておきたい.
1.1 記事の構成
2節以降では,(親記事でも触れている) Mask R-CNN 登場前夜の過去手法を簡単にだけおさえておいたのち,3節で Mask R-CNNで提案された2点の詳細を紹介する.そして,4節では,Mask R-CNN論文ではオマケ的に提案されていた人物/物体キーポイント推定(=姿勢推定)も,かなりその後の技術潮流に影響したという話を,特に管理人の専門である人物姿勢推定目線で行なう.
- 1節 概要・導入
- 2節 登場前夜の過去手法
- 3節 Mask R-CNN で提案された2点の詳細
- 3.1 [提案1] 領域提案の検出(Faster R-CNN的) → 領域提案内で前景マスク推定
- 3.2 [提案2] ROI Align : インスタンスセグメンテーション向けの「領域プーリング」度マップ」の導入
- 4節 [サブ提案] キーポイント推定ヘッドも追加し「人物・物体のキーポイント姿勢の推定」も統合
- 4.1 [管理人目線] 人物姿勢推定のその後の展開から見た,Mask R-CNNの意義
2. 登場前夜の過去手法
Mask R-CNN 登場前夜の2016年の当時のインスタセグメンテーションでは,『画像入力に対して,並行に「①Faster R-CNN 的な2ステージ物体検出ネットワーク」 と「②画像全体をセマンティックセグメンテーションする FCN」を実行し,①,②の結果出力(スコアマップ)を,最後に1つに統合して最終結果の合成スコアマップとする手法』が主流となっていた.しかしこの方針だと,たとえば当時の最新手法 FCIS ( 親記事 3.2節)でも,出力中には「マスク境界の誤差」や「アーティファクト」もまだ発生しており,実用的な結果までは得られていなかった.
そんな中「領域提案内でしかFCN処理を行わない路線の最新手法」として,Mask R-CNN [He et al., 2017] が提案された.Mask R-CNN は,COCOデータセットでの実験結果が,実用的なレベルに近づき始めた上に,その解き方もシンプルでわかりやすいことから,インスタンスセグメンテーションの決定版手法となった.
3. Mask R-CNN で提案された 2点の詳細
以下の,「Mask R-CNNのICCV2017当日の発表プレゼン動画 」のサムネイル画像にもあるように,以前もFaster R-CNNも開発・考案していたこのチームは,「Faster R-CNNの2ステージ目に,Mask推定ネットワークを追加する並行ヘッド化 (Parallel Heads) (図1)」という発想で,Mask R-CNNを考案した.
3.1節では,そのパラレルヘッドで「FCNを用いたセグメンテーション」を「2ステージ目の,並列ヘッドとして追加した」点について,3.2節では,そのために領域提案のROI PoolingをROI Alignに改良した点について,それぞれまとめる.
(英語が苦手な人でも) 必ず上記のプレゼン動画も視聴しながら以降の3.1節,3.2 節を読んでいただきたい. そうでないと,せっかく超絶わかりやすいプレゼンを著者Kaiming氏が行なった動画があるにも関わらず,2次解説である私の文章だけ読んで,もし理解が深まらなかったら,それは意味のない下手な行動(=1次資料にあたらないという勉強下手・調査下手)になってしまうのが理由.
3.1 領域提案の検出(Faster R-CNN形式): 領域提案内で前景マスク推定
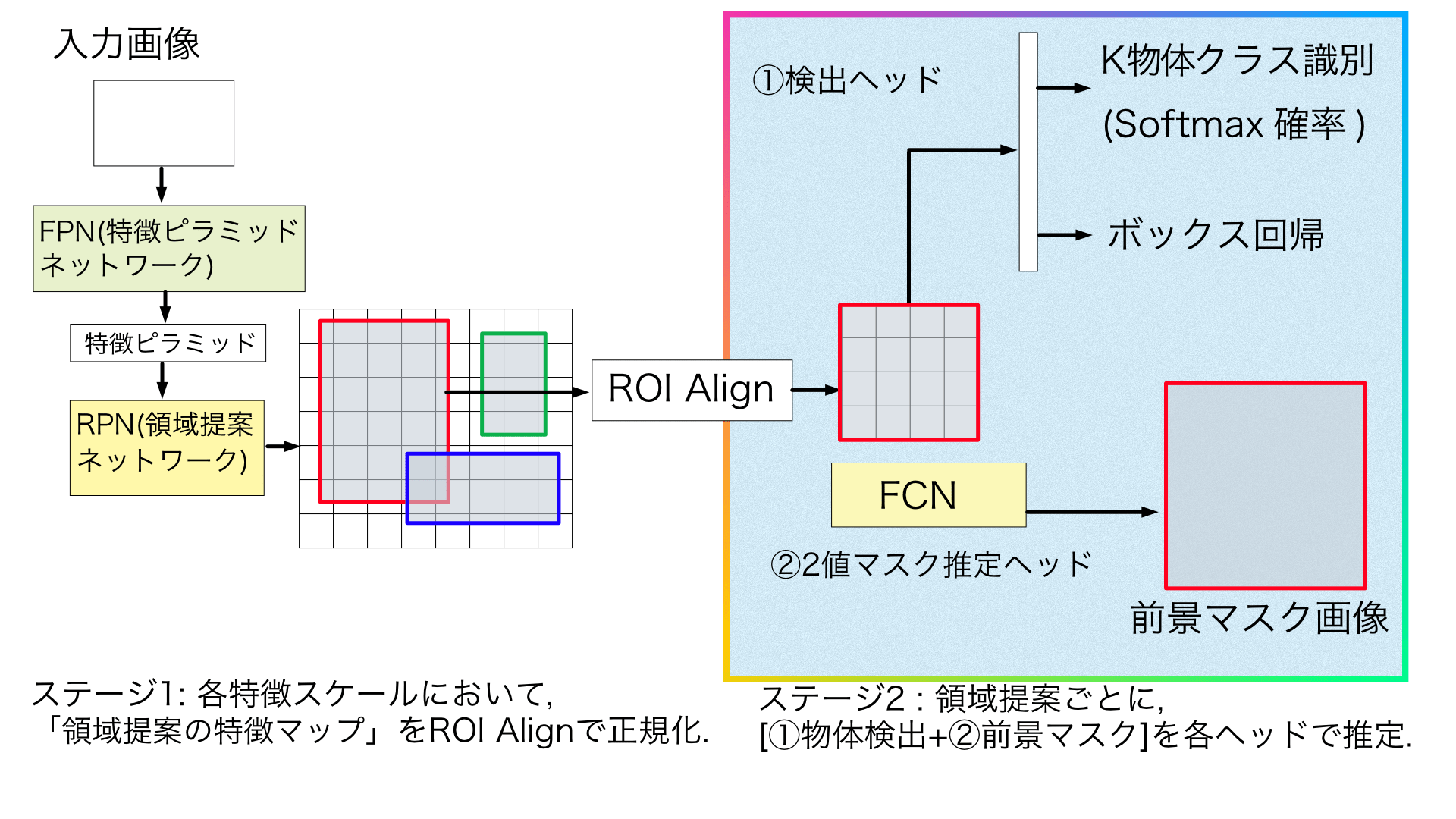
MasK R-CNN では前半ステージ(図2 左半分)には,Faster R-CNN 的な 「FPN (特徴ピラミッドネットワーク)による複数解像度での特徴マップ抽出と,その特徴マップからの「領域提案ネットワーク(RPN: Region Proposal Network)による領域候補の検出」という処理を採用している.
後半ステージ(図2 右半分)も,Faster R-CNN の後半ステージ同様の「物体検出用のヘッド(K物体クラス分類と出力ボックス回帰)」に,並行な追加ヘッドとして「FCN を用いた,ROI内の物体マスク推定ヘッド」を追加しただけの,シンプルなネットワーク構成である.
またMask R-CNN では「ROI Pooling での特徴マップへのROI 位置合わせ具合のアバウトさ」を改善した ROI Align 層 (次の 3.2節)が提案された.このROI Alignにより,RPNで検出した領域候補(Region Proposal)内の特徴を,より一合わせされたかたちで,2ステージ目へ受け渡せるようになった.
論文中の実験の章でも可視化されているように,Mask R-CNN は,旧来手法 (3.2節 FCIS など)の弱点であった「インスタンス間の,余分な誤り領域出力」が無くなり,ROI Align のおかげでマスク境界部分も正確に推定できるようになった.よって,定量評価値・定性的評価の両方で,大幅に物体領域マスク精度を更新した.
Mask R-CNN の論文では,CNNバックボーンとして当時の最先端であった ResNet / ResNeXtを Feature Pyramid Network で拡張したバックボーンが,実験で使用されている.
3.2 [提案2] ROI align : 特徴マップ座標上へのサブピクセル位置合わせ化
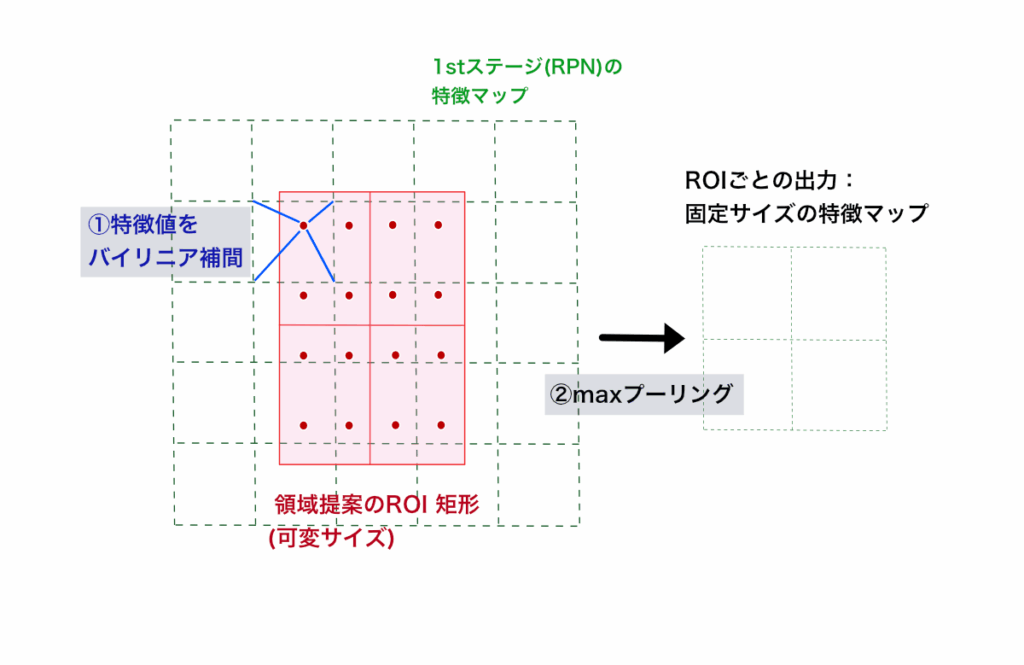
Mask R-CNNの著者らは,ROI Poolingよりも「【画像上のROI - 特徴マップ上のROI 】間の位置合わせ(alignment)」がサブピクセル精度化して正確にプーリングできるようなったROI Align (関心領域アライン) 」を提案した(図3).
ROI Alignは,領域候補の「画像座標側」から「特徴マップ」側座標系へサブピクセル精度で位置合わせされた特徴量を, Spatial Transformer [Jaderberg et al., 2015] 層に習って,特徴マップ上の周辺座標からバイリニア補間し,それらの補間生成したサブピクセル位置合わせ済みのROI領域内特徴を,②ROI矩形内で局所プーリング(最大プーリング)して2ndステージに渡す.この位置合わせプーリングによりにより,ROI Pooling よりも領域提案内の2値マスクの推定が高精度化した.
{kind=link}
またROI aling and/or Mask R-CNN は,次節4節のような人物姿勢推定の「物体のキーポイント推定」タスクにも威力を発揮し始める.
3節冒頭に埋め込んだ 口頭発表動画でのROI Alginの図解 (※そのタイムスタンプから開始)や ,詳細を書いてある,以下の「ROI alignのメイン記事」も参照のこと.
4. [サブ提案] キーポイント推定ヘッドも追加し「人物・物体のキーポイント姿勢の推定」も統合
Mask R-CNN の研究の主題は「Faster R-CNNへの物体マスク推定機能の追加」であるものの,図1の2ndステージ側マルチヘッドに「Keypoint推定ヘッド」を追加すれば,人体関節や,物体上の重要点などの「キーポイント」の位置も同時に学習できることから,Mask R-CNN の論文 [He et al., 2017] の最後の節では,「人物クラスに対しては,関節キーポイントも同時に学習させて人物姿勢推定も学習させる」ことも提案・実験された.
インスタンスマスクに加えて,$K$ 個の関節キーポイント位置をそれぞれ推定するバイナリーマスクも $K$ チャンネル追加で学習させることで,COCOデータセットの人物に対して,高精度に関節キーポイント推定 (=人物姿勢推定)もできるようになった.
3節冒頭のICCV2017のyoutube動画で,Kaiming He氏自身がスライドにも書かれてあるように,Mask R-CNNが「Easy, fast to implement and use」な構造であるから,すぐにキーポイントヘッドも追加できたわけである.逆に言うと,シンプルに色々実現されすぎて,我々 研究者のできる工夫が格段に減ってきはじめた時期が,この2017~2018年頃であるとも言えよう.
つまり,Mask R-CNN以降は,人物姿勢推定の研究でも,Mask R-CNNが引用されたりその改善が行われ始めることとなり,人物姿勢推定やその他のキーポイント推定でも「Mask R-CNNの RPN→マルチタスクヘッド構造」が重要な技術となっていった.
逆に言うと,それ以前は,人物姿勢(部位・間接キーポイント)推定や物体キーポイント推定は,Mask R-CNN以前は物体検出に統合されておらず独立しており,人物クラスや物体クラスの識別は無しで(=物体検出器にまかせて or 人物クラスしか写っていないという前提で),「人物/物体キーポイント推定のみ担当するネットワーク」が研究開発されていた(※).
※ 例えば,私の博士研究であった Poselet-Regressor や Mask R-CNNと同時期に出てきた,OpenPose やStacked Hourglass Networkもそうで,写っている人物のキーポイント推定しかなく,他の物体クラスの識別情報や,物体マスク情報は学習していない
関連記事:古典的な人物姿勢推定[ディープラーニング以前の手法]
4.1 [管理人目線] 人物姿勢推定のその後の展開から見た,Mask R-CNNの意義
Mask R-CNN [He et al., 2017] が,結構な精度で「人物検出+キーポイント推定」でも使えるようになったおかげで,私管理人の博士時代のテーマでもあった「スポーツ動画など,運動する人物の2D姿勢推定」については,研究できる内容の飽和がじきに見えてきそうという印象を受けた.実際,Mask R-CNNの2017~2018年の時期でも,静止画一枚であれば人物キーポイント推定も意味セグメンテーション推定も間違いは少ないので,その後の物体検出・インスタンスセグメンテーション・人物姿勢推定は,どれも推定精度よりも高速化・軽量化・少数ラベルからの学習などでの勝負をする研究となっていく.
ただし,私が博士論文の時に,共同研究先のパナソニック(横浜チーム)の人達と研究していた対象の「サッカーなどのチームスポーツで,スタジアム全体を撮影した映像」は,「低解像(それこそ幅60×高さ120くらい)の人物矩形検出・トラッキングし,そのROI矩形中で2D姿勢キーポイントを推定する」という設定である.これは,Mask R-CNN が学習/テスト対象とする「(COCOデータセット的な)高解像度のWeb画像で大きく写る人物・動物・物体」とは,問題設定が違い,研究としては掘りどころがあった.(特に,動画だと,時系列モデル化による学習・推定が可能なので).
4.1.1 「3D Human Body Modelを用いた3D人物姿勢&体型推定」との比較
また,画像からの人物姿勢推定の別の潮流として,「SMPLなどの3D人物体型モデルの3D形状を,画像上の人物にあてはめて3D姿勢+形状を推定する」という系統がある.
例えば,以下の動画のケンブリッジ大の研究(ICCV2021)[Sengupta et al., 2021] はその典型例で,動画の各フレーム画像中の人物部分に「3D人物形状(3D body shape)モデル」をフィットさせ,3D体型と3D姿勢の両方を推定する.
この研究のように「(あらかじめ)人物の3D形状変化を3Dモデル化しておき,画像上の2D人物に形状をあてはめる」ほうが,「OpenPoseやMask R-CNNなどの,2Dキーポイント学習による人物姿勢推定」と異なり「体型や身長の変化を,3Dモデルで吸収しやすい」というメリットが出てくる (※ 中肉中背の大人しか対象にしないなら,OpenPoseなどのように「平均的な大人の体格の,2Dキーポイント位置」を,画像から直接学習しておけばば良いが,身長体重が異なるひとたちには,こうして体格の違いも明示的に表現したほうが利点が出てくる.
これら「(SMPLなどの)3D人体形状モデルを用いた画像や点群からの人物姿勢/体型認識」は,私が博士課程で慶應の青木研究室に行き始めた当初から,ずっと触れていた技術でもある.
この「3D body shape modelも用いた画像(や点群)からの姿勢/体型推定」というテーマは,私自身も,青山学院大の鷲見教授と金子直史 先生(※ 現 東京電機大 准教授)による「3D体型モデル(SMPLなど)を用いた点群や画像からの体型推定や,画像からの人物姿勢推定」の研究へ少し加わらせて頂いていたなど「専門性のある詳しい技術」である.
また SMPLなどの3D人物体型モデルを用いた「3D 体型推定」も,私の博士課程時代の師匠,青木義満教授が教員になられた初期から,当時のお台場産総研と取り組まれていた技術テーマであり,実用での難しさもよく知っている.
ただし,こうしたの3d body modelを用いた3D人物姿勢推定/3D人物体型推定は,本記事を公開した時点まで,当サイトでは内容に触れていなかった.今後少しこのあたりの用語wiki記事を増やしたい.
※ [2025年5月記] 日本では,3D body modelは,取組んでいる人が私の周辺にしか見ないマニアックな技術テーマだったので,このサイトでも読者には響かないと思い,これまで記事は書かなかった.ただせっかくなので,SMPLの記事くらいは,書いた方がいいかも?
4.1.2 MaskR-CNNのチームによる「Dense Pose」
また Mask R-CNNを開発したFacebook/COCOチーム自身も,DensePose [Güler, Neverova, Kokkinos, 2018] で,「Mask R-CNN に,最初から3D人物形状推定のためのMaskヘッドも学習させる」というネットワークを提案した (以下の動画):
Dense Poseでは,上の関連ページであるCOCO 2020のデータ公開サイトにあるアノーテーション画像のように,「COCOデータセット画像上に,3Dボディモデルのメッシュ表面のUV座標への対応を学習させる」ことで,(3Dモデルのあてはめをスキップし)3Dボディモデルの表面座標をMask R-CNNに直接学習/推定することを提案した.
以上のような背景もあり,2017年〜2020年ごろの私としては「3D人物モデルが苦手な人は,ずっとMask R-CNNなど2D学習路線でキーポイント推定するしかなくそちらは飽和する.一方で,3D人物体型モデルのあてはめも使う研究開発者勢は,まだまだやりどころが多い」という考えであった.実際,その後の研究では,人物姿勢推定でも, 3D人物モデルや動画の3Dモーションを利用した手法の研究がメインストリーム化した (※ ただし主要国際学会では良く見るが,実用化でビジネスとして大きく成り立ってる例はまだ見ない).
まとめると,Mask R-CNNの登場で「画像からの2D物体インスタンスセグメンテーション・人物姿勢推定」の推定精度は,Mask R-CNN系の手法で一段落しはじめたので,人物キーポイント推定では,「SMPLなどの3D人物/物体/動物形状モデルの画像へのあてはめも活用したキーポイント(や6DoF姿勢)手法」が,かなり積極的に研究されていく展開になった.
5. まとめ
この記事では,Mask R-CNNについて,主提案の「マルチタスクヘッド化,ピクセル推定精度化のためのROI Alignの導入」について紹介し (3節),(マルチタスクヘッドで追加するのが容易なので)人物姿勢推定にも試されていることを述べた.
また,Mask R-CNNが「インスタンスセグメンテーション的には精度飽和の始まり」であり,その後は軽量高速化・小数ラベル学習化が大きな焦点になっていくこと(2節, 4.1節)や ,(人物姿勢推定や3D人物体型モデルが専門の私目線で)Mask R-CNNが「3D体型モデルベースでの画像からの人物姿勢&推定」に研究者が凝り始める別の起点であったこと(4節)を述べた.物体検出/インスタンスセグメンテーションのサーベイ論文読んでも,「キーポイント推定は軽視されて,人物姿勢推定目線での話が出て来ない」記事や書籍も多いことに注意し,今後もこの記事を思い返して頂きたい.
関連書籍
- Pythonで学ぶ画像認識 (機械学習実践シリーズ), 田村 雅人, 中村 克行, インプレス, 2023.
- 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之,講談社,2022.
- 5.3 畳み込み層 (p84)
- 5.8 畳み込み層の一般化 (p102)
- Probabilistic Machine Learning: An Introduction, Kevin Patrick Murphy , MIT Press, 2022.
- 14.5.2 Object Detection
- 14.5.3 Instance Segmentation
References
- [Girshick, 2015] Girshick, R. Fast r-cnn. In ICCV, 2015.
- [Güler, Neverova, Kokkinos, 2018] DensePose: Dense Human Pose Estimation In The Wild
- [He et al., 2014] He K., Zhang X., Ren, S., and Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
- [He et al., 2017] K. He, G. Gkioxari, P. Doll ́ar, R. B. Girshick, Mask r-cnn, In ICCV, 2017.
- [Jaderberg et al., 2015] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks. In NIPS, 2015.
- [Ren et al., 2015] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: towards real-time object detection with region proposal networks. In NIPS, 2015.
- [Sengupta et al., 2021] Sengupta, A., Budvytis, I., & Cipolla, R. (2021). Hierarchical kinematic probability distributions for 3D human shape and pose estimation from images in the wild. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 11219-11229).