
1. 勾配消失問題の概要と,記事の構成について
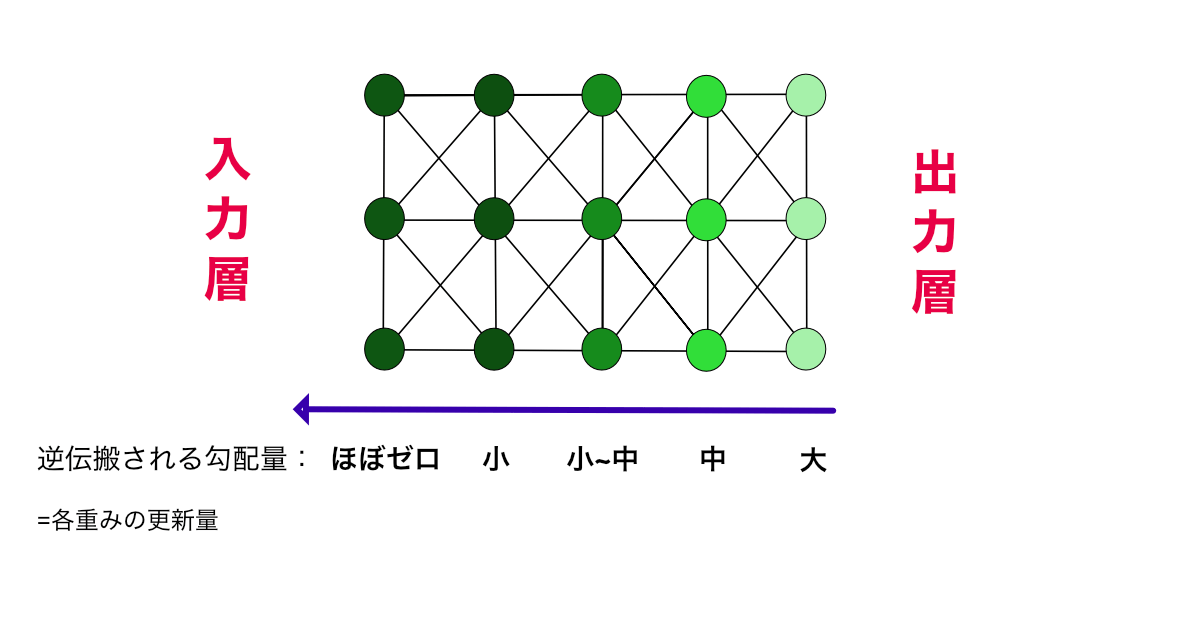
勾配消失問題(vanishing gradient problem)とは,(ディープ)ニューラルネットワークの誤差逆伝搬において,DNN内の活性化関数の勾配が,手前の方の層に行くほど,徐々に消失していきゼロ値あたりまで減ってしまい,重みの更新ができずに学習が継続できなくなる問題現象である.逆にの「勾配爆発問題(exploding gradient problem) もあり,この場合は逆伝搬していく勾配が順に大きくなり過ぎて、発散・飽和していまい,ニューラルネットの学習を途中で止めてしまう.
長くて深いディープニューラルネットをうまく学習するために,勾配消失/勾配爆発への「対処テクニック」が提案されていった(2節).それらの対処法を導入しているおかげで,CNNやTransformerは,勾配消失/勾配爆発をしないまま学習できる.
この記事では,2節でその「勾配消失・勾配爆発の対処方法のリスト化」および関連記事への紐づけを行なうことにフォーカスする.
※ 2節であげるようなDNN/CNNの部品・工夫の多くは,この「DNNを深くする上での勾配消失/爆発への対処」を念頭に創られてきたものである.この記事は,皆さんが思っている以上に「重要なまとめ記事・親記事」である.
2. 勾配消失・勾配爆発への対処法リスト.
2節では各節において,以下の勾配消失・勾配爆発への対策方法を列挙していく.
以下のKevin Murphy氏の本では,この記事と同様の節構成で,13.4.2節とそのあとの数節に,グループ化されて順に述べられている(この記事よりはかなり詳しい説明で,Murphy氏 独自の解釈もある):
- Probabilistic Machine Learning: An Introduction, Kevin P. Murphy , MIT Press, 2022.
- 13.4.2 Vanishing and Exploding gradients
よって,この2節では,そのProbabilistic Machine Learning: An Introductionでのグループ化にならった形で,各説での対策の簡潔な列挙(2.1~)と,それぞれ対策の関連記事へのリンクに留めたい.
2.1 「飽和しない活性化関数」 で対処
- Probabilistic Machine Learning: An Introduction, Kevin P. Murphy , MIT Press, 2022.
- 13.4.3.1 Non-saturating activation functions
- 14.4.3.2 Non-saturating ReLU
- 14.4.3.3 other choices (GELUの章)
初期のディープラーニング向けの活性化関数は,3層ニューラルネット時代から使っていた,双曲線関数系のシグモイド関数 やtanh 関数などが主体であったが,これらは誤差逆伝搬で大きな勾配が(出力層側から)戻って来ると,出力値が1や0へ「飽和(Saturation)」してしまいがちな関数型であり,これが 勾配消失や勾配爆発の原因となっていた.
そこで,「飽和しない関数型に設計された活性化関数」としてReLU(2011年)やLeaky ReLU (2013年)などが登場した.このおかげで出力層の全結合層にReLUをおいたCNNバックボーン「VGGNet (2015年)」が,CNNを初めて16〜19層くらいまでを深くできるようになった.
また,その後,ReLUの更なる発展型としてGELU (2016年)やSwish (2017年)なども登場した.
2.2. 残差接続ResNet/ResNextやTransformer
- Probabilistic Machine Learning: An Introduction, Kevin P. Murphy , MIT Press, 2022.
- 13.4.4 Residual connections
子記事:スキップ接続
スキップ接続・残差接続を用いた ResNet ,DenseNetなどのCNNだと
また,RNN/LSTM時代は勾配消失に苦戦していた「系列モデル&系列変換モデル」でも,Transformerがスキップ接続(残差接続)を導入したことにより,勾配消失・勾配爆発を防げるようになり,奥のの層やモジュールまで,容易に誤差を伝搬できるようになった.
関連記事:Transformerと seq2seq with attentionの違いは? [Qand A記事]
2.3 重み初期化での対処
- Probabilistic Machine Learning: An Introduction, Kevin P. Murphy , MIT Press, 2022.
- 13.4.5.1 Heuristic initialization schemes
重み初期化 (Xaiver初期化やHe初期化)も,次節のバッチ正規化(2.5節)が出てくるまでの時代では,CNN(やRNN)の勾配消失・爆発を防ぐ上で重要な役割を果たした.
最初の頃は,画像分類CNNの出力層付近に配置したReLUやシグモイド関数 に対して,Xavier初期化が効いていたが,ResNet& He初期化以降は,ReLUはブロック内に設置されたことで,スキップ接続をまたいで何度もネットワーク内に使われるようになる(これはDenseNetでも同じ).
活性化関数 や残差接続 (ResNet/ResNeXtやTransformerでも使用)が発展すると
2.3.1 初期のSiameseNet /Deep Metric Leaningでも,勾配消失・爆発が問題(かつ解決課題)であった
Re-IDやFinegrained 認識目的などで,画像からMetric leaningする際に,ディープラーニングで最初に登場したのがSiamese Networksである.このSiamese Networkは,重み初期値や,SGD学習率などをかなり慎重に調整しないと,勾配消失・勾配爆発しやすいせいで,うまく学習できない難点・使いづらさがあった.
その後,画像間のMetric Learningをする際には,3サンプルで距離を比較する 「Triplet Loss」が提案され,安定した学習が行ないやすくなり,Triplet Lossやその発展型が主に使われるようになっていった.
管理人が,慶應でポスドク研究者も兼任していた時代に,私が研究テーマ設定・指導を担当した学生も,当時このTriplet Lossによくお世話になっていた.(ちなみに基盤モデル以前の「video-language」学習がテーマ).
2.4 バッチ正規化(やレイヤー正規化)による対処
- Probabilistic Machine Learning: An Introduction, Kevin P. Murphy , MIT Press, 2022.
- 14.2.4.1 Batch nomalization
バッチ正規化は,ネットワーク中の各中間層において, 「バッチごとの出力値の正規化(normalization)」を行なうことで,各中間層での標準化(standardization)を促進し,データ分布を安定させられる.このバッチ正規化を中間層にいくつも設置しておくことで,(長くて深いネットワークでも) 各活性化関数の値が標準化され,特定の分布の値にキープされるゆえ,勾配消失・勾配爆発が発生しづらくなる.
Transformerでは,シーケンスデータ向けのレイヤー正規化が,(画像向けの)バッチ正規化の替わりに用いられる.
3. まとめ
以上,この記事では,勾配消失・勾配爆発の歴代対処法を2節でリスト化した「まとめ記事」である.
2節の詳細は各子記事を参照のこと.
本記事の構成の参考にしているProbabilistic Machine Learning: An Introduction の 13.4.2 節も参照していただきたい.
References
外部サイト
当サイトの指定参考書
【指定参考書1軍 (特にオススメ)】
中級者以上向けの,2023~2024年発売の最新テキスト3冊です.教える・育てる側である大学教員・中堅研究者層も(電子版でなく物理本)を本棚に加えたいところ.英語教科書2冊は,高価でボリュームも多いゆえ,ほんとに必要な人だけ購入した方が良いです(※ Apple Book版も安くてオススメ):
- Pythonで学ぶ画像認識 (機械学習実践シリーズ) 田村雅人,中村克行 (2023) 【紹介した記事】
- 「Foundations of Computer Vision (2024/4)」 Antonio Torralba , Phillip Isola, William T. Freeman.【紹介記事を執筆予定】
- 「Understanding Deep Learning (2023/12) 」Simon-J.-D.-Prince 著 【紹介記事を執筆予定】
【指定参考書 2軍 (オススメ)】:
- Probabilistic Machine Learning: An Introduction, Kevin Patrick Murphy, 2022.
- 深層学習 改訂第2版(機械学習プロフェッショナルシリーズ) 岡谷貴之 (2022)
- 画像認識とこの本の2冊よりも,今は1軍の英語2冊(Foundation~,Understanding ~)の方が,新しい内容の比重が多くオススメです.
- IT text : 自然言語処理の基礎 岡﨑 直観ら (2022/8月)
- 詳解 3次元点群処理 Pythonによる基礎アルゴリズムの実装, 金崎朝子, 秋月秀一, 千葉直也 (2022)


