
1. Faster R-CNN とは [概要]
Faster R-CNN とは「領域提案を用いた2ステージ型物体検出向けCNN」の元祖となった提案である [Ren et al., 2015].効率的な2ステージ計算により,「物体検出CNNの ①End-to-End 学習化と②準リアルタイム計算」を初めて達成した「アンカーありの2ステージ物体検出CNN」の元祖手法である.
この記事では,まず前身手法である R-CNN [Girshick et al., 2014] (2.1節) と Fast R-CNN [Girshick, 2015](2.2節)の概要を紹介する.その後,本題である End-to-End学習されたFaster R-CNN について紹介する(3節).また,インスタンスセグメンテーションのMask R-CNNなど,他の画像認識タスクにも応用されていくなど,のちに画像認識全体にも影響を与えていく.
関連記事:Mask R-CNN: インスタンスセグメンテーションの初期決定版手法
Faster R-CNNは,画期的な研究で貢献は大きいが,その中でも特に,以下2点の達成が主たる貢献である(※ ROI poolingは,その1つ前のFast R-CNN (2.2節)で提案済み):
- 領域提案(Region Proposal)を推定する,領域提案ネットワーク(RPN)の提案(3.1節).
- アンカーボックス(3.1.1節) の導入による計算効率化.
まず 1.2節では,Faster R-CNN 3部作の「全体の流れ」を先にまとめておくことで,読者の方々の俯瞰度を高めてから2節以降の詳細紹介に入りたい.
1.1 記事の構成
以降は,以下のような構成である:
- 1.2節:Faster R-CNN 3部作の変遷
- 2節 前身の2手法:
- 2.1 R-CNN (bboxの修正量回帰,マルチタスク学習の導入)
- 2.2 Fast R-CNN (ROI Poolingによる,後半ステージの全ニューラルネット化)
- 3節 Faster R-CNN
- 3.1 アンカーボックスの導入
- 3.2 [前半ステージ] RPN
- 3.3 [後半ステージ] Fast R-CNN
- 3.4 モデルの交互学習
- 4節 その後の発展:
- 5節 まとめ
なかでも,前半ステージと後半ステージの間をつなぐので重要な,「ROI Pooling(2.2.1節)」と「アンカーボックス(3.1節)」に焦点を当てて,紹介していきたい.
また,最後の4節では,もはや古典手法でもあるFaster R-CNNの後の「3年程度のあいだ(2016~2018あたり)に,どういう展開にFaster-RCNNの各要素から発展したかを述べる
1.2 Faster R-CNN 3部作の変遷
2014年ごろの当時は,AlexNetの登場を受け,「画像分類CNNの,物体検出への活用・横展開」が探られていたという段階にあった.
その1手法として,Faster R-CNNの著者グループは「領域提案を前後半ステージ間で受け渡す,2ステージ型物体検出手法」の,R-CNN [Girshick et al., 2014] を既に提案していた(2.1節):

- 前半ステージ(領域提案の検出):
- 非 DNN手法(selective search など)を用いて,後半ステージの処理対象領域である領域提案(region proposal)を検出する (※ Objectness領域の検出 [Cheng et al., 2014] に相当するステージ).
- 後半ステージ(領域提案のみ処理):
これに対し,まず Fast R-CNN [Girshick, 2015] (2.2節)は,後半ステージを2ヘッドのマルチタスクネットワークを用いて,「識別と回帰」を1つのネットワークに一体化することを提案した(2.2節). 画像全体をCNNバックボーンで特徴マップ化したのち,領域候補内の特徴だけをROI Poolingで取り出す.その後,2つのヘッド(小)ネットワークで,「物体クラスの識別」と「BBox修正量の回帰」をそれぞれ行う.しかし,前半は非DNNなSelective Searchのままなので,まだ全体の処理速度がかなり遅かったうえ,Selective Searchの抽出する関心領域(ROI)はノイジーであり,物体ではないもの検出も多数混ざっており,全体の物体検出精度もいまひとつであった.
そこで,Faster R-CNN [Ren et al., 2016] では,前半ステージにCNN(FCN)化した領域提案ネットワーク(RPN: Region Proposal Network)を導入し,初めて前半ステージのCNN化も達成した(3節).これにより,前半と後半でCNN特徴マップを共有化もでき計算効率化ができ,テストも高速化できた.また,前半ステージをFCNとして学習できるので,RPNの推定した領域提案の結果が高精度になり,全体の検出精度も向上した.
こうしてFaster R-CNNの提案により,ディープラーニングを用いた複数クラス物体検出手法が,初めて実用的な速度・精度に到達した.また,直後にYOLOとSSDの登場もあり,これ移行,実用レベルの複数クラス物体検出ネットワークが休息に発展していく.また,他のタスクの前処理としても,物体検出結果が活用されるようにもなっていく(物体追跡や,画像キャプション生成など)
2. 前身の2手法
画像認識CNN流行後の初期(2012~2013年頃)に,以下のような(素直な)改善案の仮説が,研究者たちの中に生まれはじめた:
- 従来の物体検出で使われてきた,HOG特徴・Haar-like特徴や,SVM・Boostingの代わりに,CNNを特徴抽出+識別器でまるごと使用すれば,CNNの恩恵で物体検出の精度が大きく向上するはず.
- ImageNetから学習する,画像認識CNNと同様に,大規模クラス数を対象とした物体検出器CNNも実現できるはず.
しかし,当時の画像認識CNN(AlexNetやVGGNet)を,従来の「スライディングウィンドウ方式の物体検出」に差し替えるだけだと,各窓で計算負荷の高いCNN順伝搬を,何万回も各ウィンドウ位置で行うはめになってしまう.この「計算非効率性」を突破していく必要があった.
そこで研究者らは,前半ステージで候補を少数にしぼり,後半ステージでだけ少数候補に対して高い負荷の計算を行うという戦略の,以下の「2ステージ構成の手法」を研究し始める:
2ステージ物体検出の構成
- 前半ステージ:
- 物体候補となる領域を,数100~数1000個だけに絞る,検出処理を行う.
- 検出された,物体領域候補BBboxを,領域提案(Region Proposal)と呼ぶ .
- 後半ステージ:
- VGGNetバックボーンが全結合層手前間でに抽出した特徴マップ([7 × 7] × 128チャンネル) から,ROI Poolingを用いて,書く領域提案のBBox範囲内に対応する特徴マップを抽出する.
- 抽出した特徴マップに「Region-CNN」を適用することで以下の2つを推定する:
- [classification] 物体クラスの識別.
- [localization] バウンディングボックスの位置・サイズの,回帰による修正.
- 後処理:
2節では,次の3節でFaster R-CNNを説明する準備として,同じ著者の研究グループから先に提案されていたシリーズ3部作の前身「R-CNN (2.1節)」「Fast R-CNN (2.2節)」の概要を先に紹介する(詳細は,それぞれの記事を参照).その後,本題のFaster R-CNNについて,次の3節で述べる.
2.1 R-CNN (Region CNN)

R-CNN(Region-CNN)は,初めて提案された2ステージ型のCNN物体検出である (図2)[Girshick et al., 2014].Pascal VOC Challenge の物体画像20クラスの検出に対して実験が行われた.
R-CNNでは,以下の処理を順に行う:
R-CNNの処理手順
- 前半ステージ(図2 左側):
- Selective Search [Uijlings et al., 2013] を使用し,後半ステージで処理する領域候補を検出.
- 後半ステージ(図2 右側)::
- 各領域候補において,以下の処理を実施:
- 領域提案のBBox内画像から,R-CNNを順伝搬し特徴ベクトルを算出.
- そのCNN特徴ベクトルを入力として,以下2つの予測を独立に実行:
- [Classification] SVMで,物体クラスを識別.
- [Localization] 線形回帰により,領域候補に対するbboxの修正量を回帰.
- 各領域候補において,以下の処理を実施:
以上の処理により,各領域の最終的な物体検出結果が得られる.
2.1.1 R-CNN の意義と課題
Pascal VOC 2010 において,CNN以前の最高性能手法であった DPM [Felzenszwalb et al., 2010] や Regionlets [Wang et al., 2013] を,mAPで10%以上更新する,大幅な性能向上を達成した.このインパクトにより,ImageNetでの多数クラス物体認識に続き,物体検出問題もCNNで取り組まれるようになっていく.
しかし,R-CNNには以下のような課題があった [Girshick et al., 2014]:
- 学習が3ステージに分離している:
- 各モデル間全体が独立して学習されて一貫性がない.
- 学習が遅い:
- 1画像につき2000個くらいの領域候補が出る.
- 従って2000回/画像も,CNNを順伝搬する必要があり,膨大に学習時間がかかる.
- テストも遅い:
- 1枚の画像を処理するのに47秒もかかる.実用的には到底使えない.
そこで,著者らは,高速化版として,次に(2番目の)Fast R-CNN (2.1節)を提案する.
2.2 Fast R-CNN とROI poolingの提案: 後半ステージの全NN化

Fast R-CNN [Girshick et al., 2015]は,R-CNNの筆頭著者であるRoss Girshick氏による,後半のR-CNNを全CNN化することで処理高速化した改善版である(図4).Fast R-CNNで導入された関心領域プーリング (ROI Pooling) により,後半ステージが完全ニューラルネット化されたことで軽量モデル化され,精度・速度の両面での向上を達成した (※ 前半ステージは変更がなくR-CNNと同じである).
2.2.1 ROI Pooling
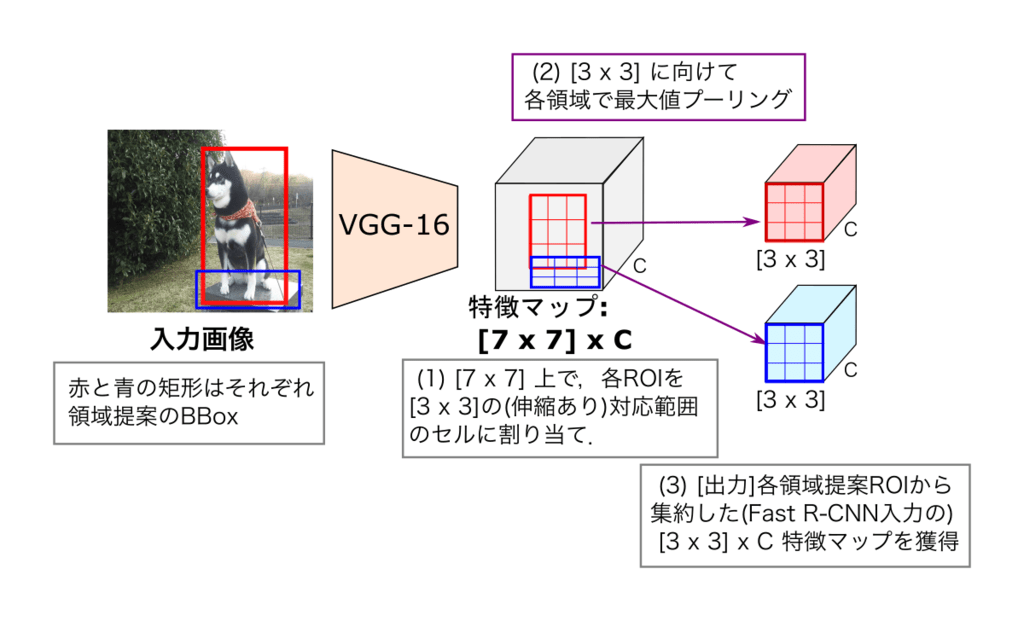
ROI pooling(関心領域プーリング)は,画像空間上の関心領域(ROI: Region of Interest)内において,そのROI領域に対応する特徴マップにおいて,空間グリッド領域ごとに,局所的な最大値プーリングをおこなう(微分可能な)プーリング層である(図5).
VGGNetで抽出したCNN特徴マップ(pool5層後)の [H x W] x C 上において(図5の例では [7 x 7] x C),入力画像上の領域提案ROIに対応する範囲から,最大値プーリングを用いて固定縦横サイズ [h x w] x C (図5では [3 x 3] x C)に,特徴を集約する.これにより,前半の領域提案のROI矩形サイズがバラバラであっても,ROI Pooling実施後は「毎回同じ固定サイズの特徴マップ」に統一されるので,2ステージ目のFast R-CNN の入力サイズを統一することができる.
ただ,ROI Align (関心領域 アライン) (Mask R-CNNで提案)のように,特徴マップ上のサブピクセル位置での特徴値をとろうとはしておらず,画像の座標を,特徴マップ側の座標に量子化してあてはめて生の特徴をそのまま集約(プーリング)して2ステージに渡しているだけであった.それだお領域提案のバウンディングボックス矩形内とはややずれている特徴量をもらってしまっているので,ROI Align (関心領域 アライン)やそれ以降の局所プーリング手法を用いた方が好ましい.(詳しくは以下のROI alignの記事で).
2.2.2 後半ステージ: Fast R-CNN
まずROI pooling済みの領域提案内の特徴マップ [h x w] x C を,フラット化した特徴ベクトルを作り,全結合層2層を通してROI表現を推定する (図4-右).その結果の,ROI表現ベクトルを入力にして,2つの全結合層ヘッドに「 (1) 物体クラス」「(2) バウンディングボックス回帰」をそれぞれ学習する.
テスト時:
後半ステージのFast R-CNNでは,以下の手順でテストの計算を行う(図4 右側):
処理手順
- 画像全体を先にCNNバックボーンに入力し,画像全体の特徴マップを計算.
- 各$i$番目の領域提案に対して,以下の計算を行う:
- ROI Pooling層で,領域提案$i$の特徴マップをプーリング.
- MLP(全結合層2層)により,領域提案$i$の特徴ベクトルを抽出.
- 全結合層のヘッド2つにより「softmax確率ベクトルをKクラス分」と「bboxの修正量 × Kクラス分」をそれぞれ推定.
- クラス確率最大のクラス$k$と.そのクラスに対応するbbox修正量(のみ)を出力.
- (NMS)非極大値抑制を行い,その結果を最終的な検出結果として出力.
以上がテスト時の処理である.
学習時:正解ROIごとの,マルチタスク損失による学習
Fast R-CNNの(SGD)学習では,物体クラス$u$にラベル付されたROIごとに,以下のマルチタスク損失関数で誤差を計算する:
\[
\mathcal{L}_{fast}(\bm{p},u,\bm{t}^u,\bm{v}) = \mathcal{L}_{cls}(\bm{p},u) + \lambda [ u \geq 1]\mathcal{L}_{bbox}(\bm{t}^u, \bm{t}) \tag{2.1}
\]
($[u \geq 1]$は,アイバーソンの記法(Wikipedia).$u>1$が真の時に値が1で,偽のときは値が0)
式(2.1)で使用されている各変数は以下の通りである:
- $u$: 正解クラスのラベル; $u \in \{0,.....,K \}$.$u = 0$が背景クラス.
- $\bm{p}$: softmax出力の$K+1$次元クラス確率ベクトル; $\bm{p} = (p_0,p_1,\ldots, p_K)$
- $\bm{v}$: 正解bboxの位置とサイズ; $\bm{v} = (v_x,v_y,v_w,v_h)$
- $\bm{t}^u$: 推定されたbboxの修正量; $\bm{t}^u = (t_x^u,t_y^u,t_w^u,t_h^u)$
式(2.1)のクラス識別の損失には,事後確率の負の対数を用いる:
\[ \mathcal{L}_{cls}(\bm{p},u) = - \log p^u \tag{2.2}\]
式(2.1)のbbox修正量回帰の損失には,外れ値に頑健な,Smooth L1損失を用いる:
\[\mathcal{L}_{bbox} (\bm{v}, \bm{t} )= \sum_{i \in \{ x,y,w,h \}} L_1^{smooth}(t_i^u-v_i)\tag{2.3}\]
\[
L_1^{smooth}(x)=\begin{cases}
0.5x^2 & if |x| < 1 \\
|x| - 0.5 & otherwise
\end{cases}
\tag{2.4}
\]
式(2.1)の損失関数$\mathcal{L}_{fast}$を用いてFast R-CNN を学習することに,R-CNNと比べて高速化と性能向上に成功した.こうしてFast R-CNN は,1つのニューラルネットワークに統一できた.
2.2.3 Fast R-CNN の課題
Fast R-CNNは良くなったが,前半ステージは非Deep手法で精度は微妙なSelective Searchのままなので,領域提案の過検出・未検出は起こりがちである.つまり,前段ステージが精度向上のボトルネックである点が,解決できていなかった.したがって,前半ステージもCNN化して,安定した領域提案検出を行いたいという動機のもと,この記事の本題であるFaster R-CNN(3節)が登場する.
3. Faster R-CNN

Faster R-CNN [Ren et al., 2015] は,Fast R-CNNの前半ステージを領域提案ネットワーク(RPN: Region Proposal Network)に差し替えたものである(図6).
Faster R-CNN の2ステージ構成は,以下のようになっている:
Faster R-CNNの処理手順
- RPN [前半ステージ] (3.1 節):
- アンカーボックス方式で,領域提案のバウンディングボックス群を検出.
- Fast R-CNN [後半ステージ] (3.2 節):
- RPNで計算した,全画像の特徴マップを,入力特徴に用いる.
- ROI Poolingした領域特徴を入力に,以下の2タスクを並列に実施:
- 識別ヘッド[タスク1]: 領域提案を$N$クラス識別.
- 回帰ヘッド[タスク2]: 領域提案を残差回帰して洗練.
RPNでは,特徴マップグリッド上の各グリッドの中心 =アンカー(Anchor) 点に対して,領域候補の事前分布(Prior)群に相当するアンカーボックス(Anchor Box) を,K個用意する(3.1.1節).そして,各アンカー位置において,K個のアンカーボックス群から「Objectness(物体らしさ)値 + バウンディングボックス 修正量の回帰値 」を学習する.このRPNの導入により,Faster R-CNNは,高速かつ正確でありながらも,物体内遮蔽・物体間遮蔽の双方について頑健な領域候補の検出が,1ステージ目で可能となった.
また2ステージ間で,序盤の特徴マップ抽出層(図6オレンジ色の枠内:VGGNet Pool5 + [3 × 3] 畳み込み層)を 全画像の特徴マップを共有する.これにより2モデルとも同一の特徴マップを用いて,残りの推定器ヘッドを学習できるようになった (3.2節).以上より,後半ステージ用の正解ラベルも加味した「共有畳み込み層群」を学習できるようになり,RPN(1ステージ)も,高品質な領域候補検出が可能となった(3.4節)
3.1 前半: 領域提案ネットワーク(RPN)

前半ステージのRPNをFCN化したことで,RPNの特徴マップを再利用して,後半ステージの推定処理を実施できるようになった.これにより,後半ステージでイチから画像の特徴マップを再度計算する必要性がなくなり,計算効率が向上した.更に,正解BBoxからRPNを学習できるので,前半の領域候補検出の精度も向上した.(※ RPNの詳細は,ここから,以下のRPNのみ主題の記事へ移動しました)
3.2 [後半] Faster R-CNN
後半ステージのFaster R-CNNは,Fast R-CNN [Girshick, 2015] のネットワーク構造の各全結合層を,すべて畳み込み層に変更したネットワークに,RPNと同じ畳み込み層を前半に共有したネットワークである (図6 右側).
Fast R-CNN [Girshick, 2015] と同じマルチタスク出力であるので,損失関数の式(2.1)を用いて学習する (2.2.2節).
3.3 モデルの交互学習
RPNが完全畳込みネットワークであるおかげで,RPNの出力「入力画像全体の特徴マップ」は,そのまま後半ステージの「Fast R-CNNの入力」として共有される.よって2モデル間で共有する畳み込み層は固定しながら,RPNとFaster-RCNNの2つを,以下の手順で交互に学習する:
Faster R-CNNの学習処理
- 初期化 (RPNのみ初期化):
- Faster R-CNNの学習:
- ステップ1で学習した領域候補群を元に,Faster R-CNNを学習.
- RPNの再学習:
- ステップ2で学習したFaster R-CNNからの検出結果を元に,2者が共有する畳み込み層は固定しながら,RPNにのみにある後方の層のみfine-tuningする.
- これにより,2モデルが畳み込み層を共有.
- Faster R-CNNの再学習:
- Faster R-CNNを,共有畳み込み層は固定してFine-turingする.
- ステップ3と4を,損失が終了値以下に減るまで繰り返す.
この手順により,2ステージのモデルに一貫性を持たせることができる.したがって,RPNが出力する領域候補が,きちんとFaster R-CNNの事前分布としてはたらく結果となる.こうして前半で高精度な領域候補の出力ができ,なおかつFaster R-CNNによる識別・回帰に適した特徴マップを提供できるようになった.
4. その後3年あたりの発展
Faster R-CNN は,その登場後3年ほどで,以下の3系統の方向へと発展が展開されていくことになる
- 「1ステージの物体検出手法」や「アンカーボックス無しでキーポイント推定を利用する手法(CenterNet/CornerNetなど)」の登場.
- Feature Pyramid Networksなどの,画像認識CNNむけマルチスケール特徴量の発展 (※)
- (4.2節) 2ステージ目をマルチヘッド化してセグメンテーションやキーポイント推定も可能にする「Mask R-CNN 」[He et al., 2017]への拡張.
より詳しい話は,物体検出の記事の最後にまとめているので確認してほしい.
5. Faster R-CNN のまとめ
この記事では2ステージ型物体検出の基本形である,Faster R-CNNについて紹介した.
前身の「R-CNNとFast R-CNN」についても紹介し,Fast R-CNNの構成要素でもある「bbox修正量のパラメタライズ」「マルチタスク損失による学習」「ROI Pooling」について,準備知識として先に述べた.
それを踏まえて,Faster R-CNNの紹介では,重要な内容として「領域提案ネットワーク(1ステージ目のFCN化)」「アンカーボックスの利用」と,「2ステージの特徴計算層(FCN)の共有」について紹介した.
References
- [Cheng et al., 2014] Cheng, M. M., Zhang, Z., Lin, W. Y., & Torr, P. (2014). BING: Binarized normed gradients for objectness estimation at 300fps. In CVPR 2014.
- [Felzenszwalb et al., 2008] P. Felzenszwalb, D. McAllester, and D. Ramanan. A discriminatively trained, multiscale, deformable part model. In CVPR, 2008.
- [Felzenszwalb et al., 2010] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.
- [Girshick et al., 2014] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
- [Girshick, 2015] Girshick, R. Fast r-cnn. In ICCV, 2015.
- [He et al., 2014] He K., Zhang X., Ren, S., and Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
- [He et al., 2017] K. He, G. Gkioxari, P. Doll ́ar, R. B. Girshick, Mask r-cnn, In ICCV, 2017.
- [Ren et al., 2015] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: towards real-time object detection with region proposal networks. In NIPS, 2015.
- [Uijlings et al., 2013] Uijlings, J. R., Van De Sande, K. E., Gevers, T., and Smeulders, A. W. Selective search for object recognition. International journal of computer vision, 104(2), 154–171.
- [Wang et al., 2013] X.Wang, M.Yang, S.Zhu, and Y.Lin. Regionlets for generic object detection. In ICCV, 2013.
- [Wu et al., 2020] Wu, X., Sahoo, D., & Hoi, S. C. (2020). Recent advances in deep learning for object detection. Neurocomputing, 396, 39-64.
関連書籍
- 画像認識(機械学習プロフェッショナルシリーズ),原田達也,講談社,2017.
- 7.6.3 Faster R-CNN (p 218)
- 7.6.2 Fast R-CNN (p216)
- 7.6.1 R-CNN (p214)