
1. Encoder-Decoder ネットワークとは [概要]
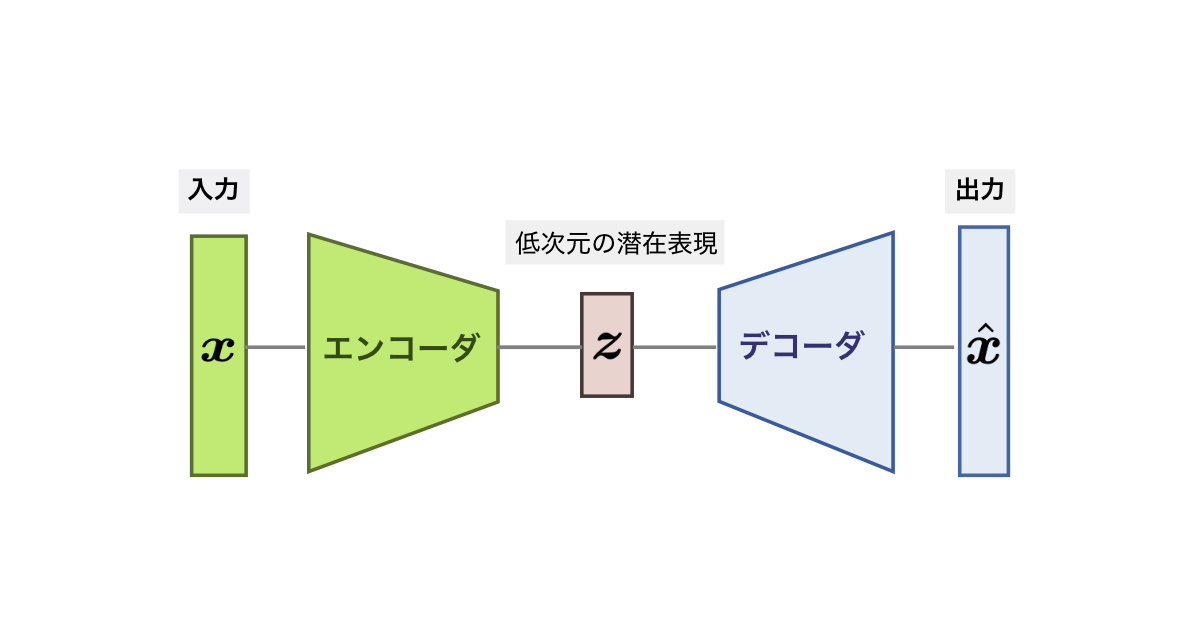
Encoder-Decoder ネットワーク (構造)とは,オートエンコーダ以降のディープニューラルネットワークでよく用いられる「入出力を端として,中央部の次元を低くし,その中央部の左右で対称形を成すネットワーク構造」である (図1).その真ん中を細くする設計構造から,「砂時計型(hour-glass)」とも形容されるる.つまりは,EncoderとDecoderが対称構造をなして,元の情報を変換・復元する(多くはdeppな)ニューラルネットワークのことを,俗にEncoder-Decoderモデルとか(Deep) Encoder-Decoderネットワークと呼ぶことが多い.
この記事の3節では,生成モデルや変換モデルによく用いる,(画像変換向け)畳み込みEncoder-Decoder(3.1節)と,自然言語処理や音声認識, TTS(Text-to-Speech)などに用いる,Transformerなどのトークン系列Encoder-Decoder(3.2節)の2つを「一般化して どちらもEncoder-Decoderの派生型である」と俯瞰視・共通視できるようにする.
これにより,今後は読者が「共通のEncoder-Decoderという観点から,多くの各種ネットワーク構造を判別・分析しやすくなる」ことを狙う.
※ 2025年6月に,この「3派生型での分類」への,記事の再編集をおこなった.
2020年前後以降に,deepネット構造の新たな主役にもなってきた「Transformer 系モデル(コンピュータビジョンだと,ViTやDETRなど)」への理解も,この記事で高まるはず.
1.1 まず「代表的なDeep Encoder-Decoder構造の使用例」を見てみると....
Encoder-Decoderネットワークのうち,たとえば「コンピュータビジョン向けの砂時計型のモデル」として,各タスクを解くために提案された「代表的なEncoder-Decoder構造」として,以下のようなものがある:
- オートエンコーダ(Autoendoder):特徴ベクトルや画像特徴マップの,次元削減を行う(2節)
- Denoising AutoEncoder (※ 記事未作成): 雑音ありデータと,綺麗なデータの間で学習することで,ノイズに強い中間表現をオートエンコードすることができる.
- 変分オートエンコーダ(VAE):ガウス潜在変数を学習できる,オートエンコーダの進化版の深層生成モデル.
- SegNet:RGBシーン画像向けの,セマンティックセグメンテーションネットワーク.
- U-Net:モノクロ医用画像向けの,セマンティックセグメンテーションネットワーク.
- pix2pix:画像変換.各画素の意味は保ちつつ,画像スタイルを変換
- Stacked Hourglass Network: 人物姿勢推定 ※ 砂時計モジュールを,N回繰り返す構造.(3.1節)
- 画像補完や超解像などの逆問題・画像復元系 (3.1節)
- 単眼画像からのデプス推定などの問題 (3.1節)
このような単なるタスクの羅列や図1のイメージだけでは,「ああ,どれも砂時計型のネットワーク構造ではあるなあ...」くらいの理解に留まり,それぞれの「Encoder-Decoderネットワークの違い/共通点」が,よく掴めないはずである.よって3節では,これらを,管理人独自の「Encoder-Decoderネットワークの派生型3タイプ」に分類することで,俯瞰度を上げて理解しやすくなるようにしたい.
それでは3節の分類を行なう前に,2節で「オートエンコーダ」の話を済ませる.
2. 「オートエンコーダ 」でのEncoder-Decoder構造の活用
Autocodingを行なう目的で,Encoder-Decoderネットワーク(図1)を組む,オートエンコーダ [Hinton and Zemel 1994] や 画像の変分オートエンコーダ(VAE) [Kingma and Welling, 2014] のForward処理では,前半の各層でEncoderを用いてダウンサンプリング・符号化を行い,bottleneck層にむけて中間コードを生成する.そして,後半各層では,bottleneckの中間コードからDecoderを用いて復号化を行い,元画像のサイズまで転置畳み込みでアップサンプリングも行なっていき,最後にサイズが戻った元画像を出力として復元する.
学習の際に,オートエンコーダ や,変分オートエンコーダ(VAE) では,「(符号化理論は特に用いていない)ディープラーニング的な損失関数」で,データから表現を学習し,それと同時に中間層表現の次元圧縮もおこなう.つまり,DNNで Encoder-Decoder構造を使用する場合は,情報理論や,古典的な符号化理論は,積極的には活用されていないのだが,「auto-encoder」という名前が,何らかの数式などに基づいて「情報理論的な符号化もしていそうな」のは,(特に,名前の意味をちゃんと考える人には)ややこしい.
MLコミュニティの一部で,「中央のボトルネックに,情報幾何理論などを積極活用する潮流」もあったのだが,機械学習の基礎理論寄りの話で,難易度が少し高く&上級者向けのテクニカルな話である(※)ので,この記事では深く掘り下げはしない.
(※)例えば「Probabilitic Machine Leraning book : An Introduction 」の著者でもあるKevin Patrick Murphy氏のチームが,DEEP VARIATIONAL INFORMATION BOTTLENECK [Alemi et al., 2017]という「Information Bottleneck [Tishby et al., 1999] の変分近似」を提案していたが,この路線は,その後 deep contrastive learning や,マルチモーダル学習界隈でも引用・応用されていた.しかし,機械学習理論系のトップ学会中心の動き(ICLRやNeurIPS,時々CVPRでも王朝)であったゆえ,中身もやや数理的でマニアックである.それもあり,「中級者向けの内容までに留めているこのサイト」では,詳しい話まではしない.
3 . 画像変換とトークン系列変換への派生.
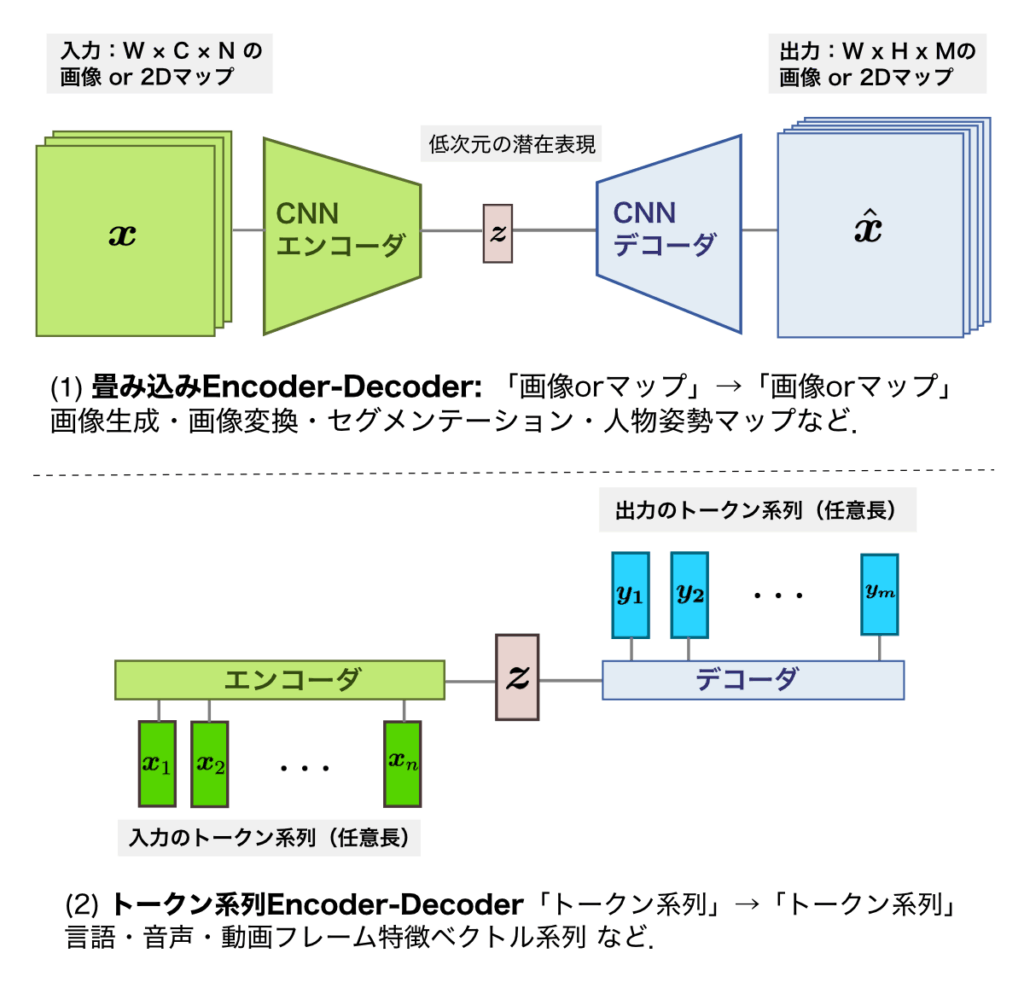
この3節では, (画像変換むけと系列変換むけのEncoder/Decoderの組み合わせごとに,Encoder-Decoderネットワーク構造を,以下の派生型3パターンに分類する:
- ①畳み込みEncoder-Decoder(3. 1節),[ 図2-(1)]
- 画像変換 向け:「画像→画像」
- ②トークン系列Encoder-Decoder(3.2節)[図2-(2)]
- トークン系列変換 向け:「系列→系列」
- ③ MIX型 Encoder Decoder (3.3節) [図3]
- 「画像→系列」 変換 ⇔ 「系列→画像 」変換.
また,各サブ節(3.1~3.3)では,①〜③派生型のEncoder-Decoderネットワークが使われる「タスク例」を紹介してことで,派生型3パターンとの対応付けをしたい.
3.1 [派生型①] 畳み込み Encoder -Decoder
例えば,画像変換やセマンティックセグメンテーションに,人物姿勢推定での「K個の関節のマップ画像群の推定」などに用いられてい
画像・2Dマップの入出力向けの畳み込みEncoder-Decoderネットワーク[図2-1]は,以下の2つのサブネットワークから構成される(1.1節)」
- Encoderネットワーク:
- 入力画像 or 特徴マップを解釈・符号化する(※ 画像認識で言うと「特徴抽出」する).
- Decoderネットワーク:
- 中間表現を,アップサンプリングしていき,元の空間サイズまで戻して出力画像or 2Dマップを生成する.
- 畳み込みEncoder-Decoderネットワーク[図2-(1)]は,各層で以下の処理を行う
セマンティックセグメンテーションのような「画像->意味画像」でよく使用されるネットワーク構造でも,Encoder-Decoderモデルを構成することが多い.ただし,入出力は(同画像サイズの)別の画像同士であり,オートエンコーダのように同じ画像同士でしているわけではない点に注意されたい.両者はネットワークはEncoder-Decoder型で共通だが,入出力ペアは別物なので,変換モデルを学習する.
また,セマンティックセグメンテーションとは逆方向の「意味画像->画像」間の変換を行う画像変換(Image-to-Image Translation)においても,初期モデルのpix2pixでは,素直に(U-Netライクな)砂時計型の畳み込みEncoder-Decoderを使用している.
画像補完(image inpainting)や超解像(super resolution)などの「画像復元」系の問題を,データドリブンに深層学習して解く場合においても,画像変換と同じく「劣化画像 -> 元画像」の復元を畳み込みEncoder-Decoderネットワークに学習する.
また,「カラー画像からの(単眼)デプス画像推定」などでも,畳み込みEncoder-Decoderを用いる事が多い.
3.2 [派生型②] トークン系列向けの系列Encoder-Decoder
系列同士を変換する系列対系列変換が目的のトークン系列Encoder-Decoder(図2-2)が,機械翻訳や,音声認識・Text-to-Speechや音声認識などで用いられてきた.トークン系列Encoder-Decoder「入力系列を解釈するEncoder」と,出力系列を生成する「Decoder」の,2つのサブネットワークから構成され,
系列対系列変の各タスクでは,入力系列も出力系列も,共に「系列長が可変」である.ゆえに,可変系列に対応できる「RNNモデル(LSTM,GRU , RNNLMの文生成)」や,「Transformerエンコーダ・Transformerデコーダ」などが,EncoderとDecoderに用いられる.また,これらの系列変換の各種問題向けのEncoder-Decoderでは,アテンション機構を同時に利用することが標準的だ.
こうしたトークン系列データ間のEncoder-Decoderは,当初seq2seqと名付けられ,その後,アテンション中心で構成されたTransformerへと発展した(図2).
アテンション機構を用いる「seq2seq with attentionやTransformer」の場合,Encoder-Decoder間の各層間がかなり密にお互いが繋がっている(※スキップ接続や,アテンション重みを通じて接続).よって,EncoderとDecoderが明確には分離独立しておらず2者間が複雑かつ適応的に作用する.
一方『一般化言語モデル(GPTやBERTなど)の自己教師有り事前学習』についても,それら「BERT」や「GPT」は,TransformerのEncoderもしくはDecoderの片方のみを用いていることが多く,系列Encoder-Decoderではない.ただ,その後登場したBERTの改善手法である「BART」は,(Denoising Auto-) Encoder-Decoderである.
3.3 [派生型③] MIX型Encoder-Decoder
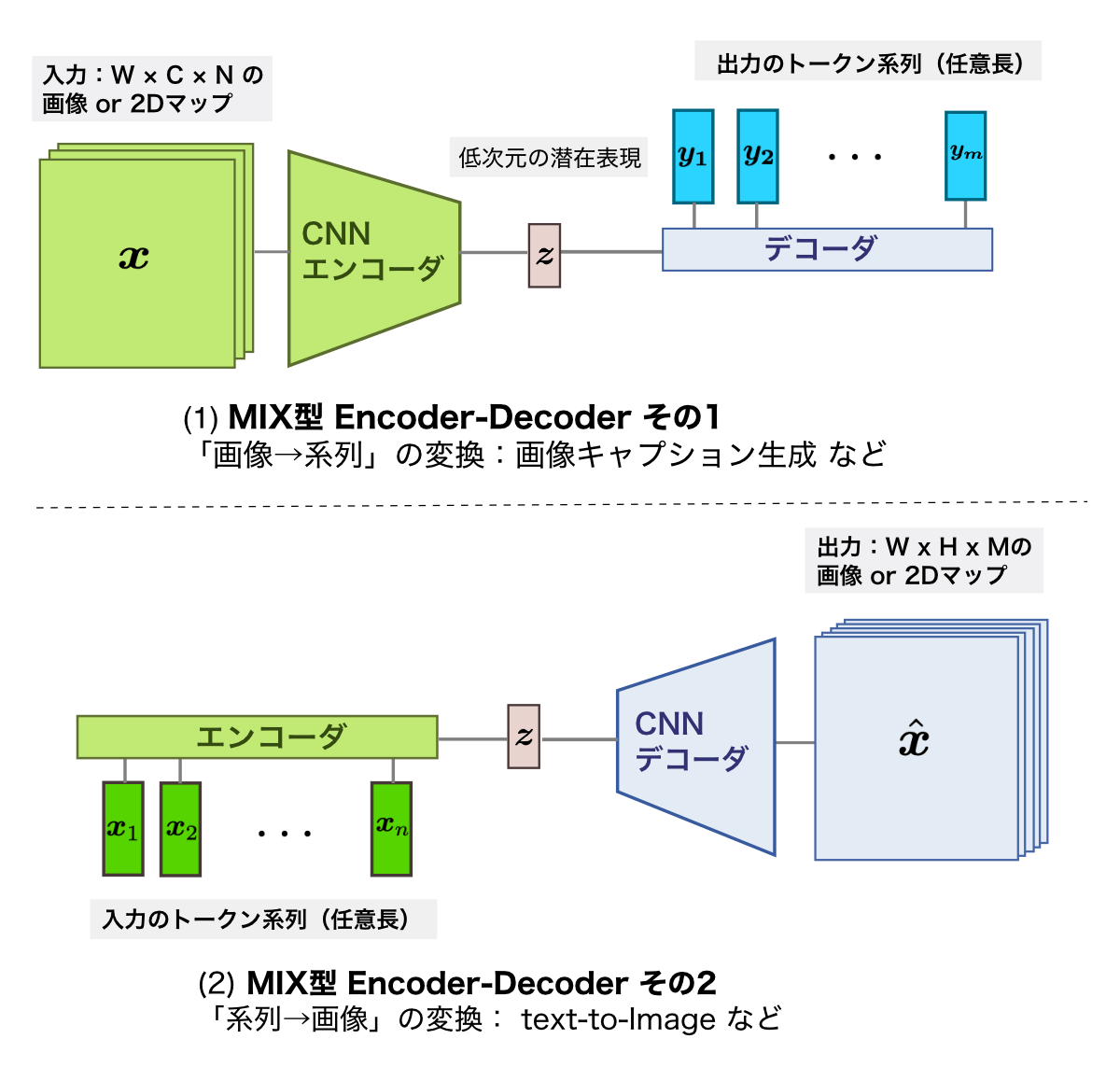
最後の派生型である③ MIX型 Encoder-Decoder (図3) は,①,② (図2)の部品を半分ずつ使うもので,画像と系列を橋渡すタスクで用いるEncoder-Decoderネットワークである.つまり,「画像→系列の変換 (図3-1)」や,その逆変換タスクの「系列→画像 変換 図3-(2)」を行なう際のEncoder-Decoderネットワークである.
Vision-Languageの各タスクは,このMIX型 Encoder-Decoderを用いる典型である.たとえば,「画像キャプション生成 :画像→テキスト」や,「text-to-Image変換:テキスト→画像」などでは,MIX型のEncoder-Decoderネットワークを組んで学習しがちである.
あと,物体検出のDETR (Detection Transformer) も,「画像CNN→Transformer」の処理構成であるので,全体は MIX型 Encoder-Decoder的である (CNNとTransformerが別もので分離しており,全体のEnd-to-Endに学習はできないが...).CNNだけがEncoderなのか,TransformerエンコーダまでがEncoderなのか,どちらで解釈するかは微妙な所である....
4. まとめ
以上,この記事では,(Deep) Encoder-Decoderネットワークについて,俯瞰的な視点やカテゴリ分け発想を読者に授けたいという目的で,その典型的なネットワーク構造を3つの派生型に分類し,それぞれの派生型を用いて解かれるタスクも整理することを行った.
私のように,「画像変換モデル」や「Vision-Language/マルチモーダル変換」の研究/開発経験があれば,この記事での分類はなんとなくはわかっていた分類や区別できていとは思うものの,本記事を書き始めた頃以前は,ちゃんと整理している論文・資料は少なく, (画像系とテキスト系列系を混ぜての,Deep Encoder-Decoderの整理/分類も,レアなはず).
また,Encoder-Decoderについて整理するのは,Transformer登場後の昨今重要である.よって,Transformer使用したモデルを調べていて混乱したり,または自分でネットワーク構造や取組むタスク・問いのアイデア出しをする時などに,この記事を復習して頂くと,お役に立てることを期待している.
参考書籍
- Pythonで学ぶ画像認識 (機械学習実践シリーズ) (📖紹介記事), 田村 雅人, 中村 克行, インプレス, 2023.
- 5章 Transformerによる手法 - DETRを実装してみよう: DETR の構造」(p224) .
- この節の「図5-30 」が「DETRの内部の,どこまでがCNNの担当で,どこからがEncoder-Decoder(Transformer)が担当なのかがよく分かる良い図.
- このあとのTrasnformerデコーダ層 (p255)
- 6章 画像キャプショニング 3節 CNN-LSTMによる手法 (p300)
- 5章 Transformerによる手法 - DETRを実装してみよう: DETR の構造」(p224) .
- 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之,講談社,2022.
- 第2版になりseq2seq やアテンション,Transformerの章が追加されている
- Probabilistic Machine Learning : An Introduction, Kevin Patrick Murphy, MIT press, 2022.
- 14.5.4 Semantic Segmentation
- 15.2.3 Seq2Seq (sequence translation)
- 19.3.6.1 Variational autoencoders
- 生成Deep Learning David Foster 著, オライリージャパン, 2020.
References
- [Alemi et al., 2017] Alexander A. Alemi, Ian Fischer, Joshua V. Dillon, and Kevin Murphy. Deep variational information bottleneck. In International Conference on Learning Representations, 2017.
- [Hinton and Zemel 1994] Geoffrey E Hinton and Richard S Zemel. Autoencoders, minimum description length, and helmholtz free energy. In NIPS, 1994.
- [Kingma and Welling, 2014] D. P. Kingma and M. Welling. Auto-encoding variational bayes. In ICLR, 2014
- [Tishby et al., 1999] Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method. In Allerton Conference on Communication, Control, and Computing, 1999.
外部参考サイト
指定参考書
【指定参考書1軍 (特にオススメ)】
中級者以上向けの,2023~2024年発売の最新テキスト3冊です.教える・育てる側である大学教員・中堅研究者層も(電子版でなく物理本)を本棚に加えたいところ.英語教科書2冊は,高価でボリュームも多いゆえ,ほんとに必要な人だけ購入した方が良いです(※ Apple Book版も安くてオススメ):
- Pythonで学ぶ画像認識 (機械学習実践シリーズ) 田村雅人,中村克行 (2023) 【紹介した記事】
- 「Foundations of Computer Vision (2024/4)」 Antonio Torralba , Phillip Isola, William T. Freeman.【紹介記事を執筆予定】
- 「Understanding Deep Learning (2023/12) 」Simon-J.-D.-Prince 著 【紹介記事を執筆予定】
【指定参考書 2軍 (オススメ)】:
- Probabilistic Machine Learning: An Introduction, Kevin Patrick Murphy, 2022.
- 深層学習 改訂第2版(機械学習プロフェッショナルシリーズ) 岡谷貴之 (2022)
- 画像認識とこの本の2冊よりも,今は1軍の英語2冊(Foundation~,Understanding ~)の方が,新しい内容の比重が多くオススメです.
- IT text : 自然言語処理の基礎 岡﨑 直観ら (2022/8月)
- 詳解 3次元点群処理 Pythonによる基礎アルゴリズムの実装, 金崎朝子, 秋月秀一, 千葉直也 (2022)


